Runway’s Gen-3 is one of the best artificial intelligence video models currently available and it just got a lot better with the launch of the highly anticipated image-to-video feature.
While Gen-3 has a surprisingly good image generation model, making its text-to-video one of the best available, it struggles with character consistency or hyperrealism. Both problems are solved by giving it a starting image instead of just using text.
Image-to-video using Gen-3 also allows for motion or text prompts to steer how the AI model should generate the 10-second initial video, starting with the image. This can be AI-generated or a photo taken with a camera — the AI can then make it move.
Gen-3 also works with Runway’s lip-sync feature, meaning you can give it an image of a character, animate that image and then add accurate speech to the animated clip.
Why is image-to-video significant?
Until AI video tools get the same character consistency features found in tools like Leonardo, Midjourney, and Ideogram their use for longer storytelling is limited. This doesn’t just apply to people but also to environments and objects.
While you can in theory use text-to-video to create a short film, using descriptive language to get as close to consistency across frames as possible, there will also be discrepancies.
Starting with an image ensures, at least for the most part, that the generated video follows your aesthetic and keeps the same scenes and characters across multiple videos. It also means you can make use of different AI video tools and keep the same visual style.
In my own experiments, I’ve also found that when you start with an image the overall quality of both the image and the motion is better than if you just use text. The next step is for Runway to upgrade its video-to-video model to allow for motion transfer with style changes.
Putting Runway Gen-3 mage-to-video to the test
Get started with Gen-3 Alpha Image to Video.Learn how with today’s Runway Academy. pic.twitter.com/Mbw0eqOjtoJuly 30, 2024
To put Runway’s Gen-3 image-to-video to the test I used Midjourney to create a character. In this case a middle-aged geek.
I then created a series of images of our geek doing different activities using the Midjourney consistent character feature. I then animated each image using Runway.
Some of the animations were made without a text prompt, others did use a prompt to steer the motion but it didn’t always make a massive difference. In the one video, I needed to work to properly steer the motion — my character playing basketball — adding a text prompt made it worse.
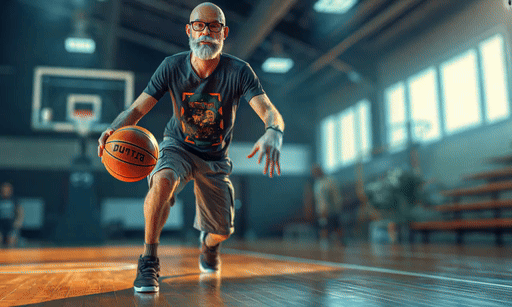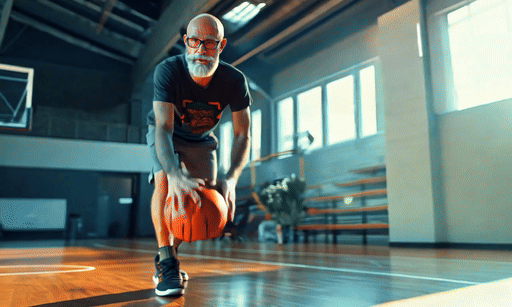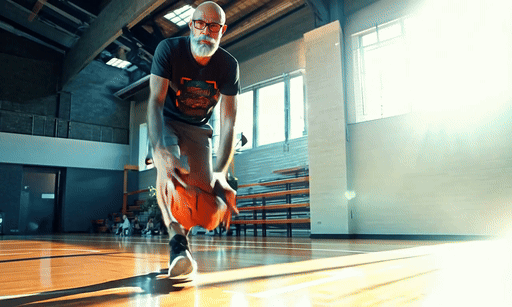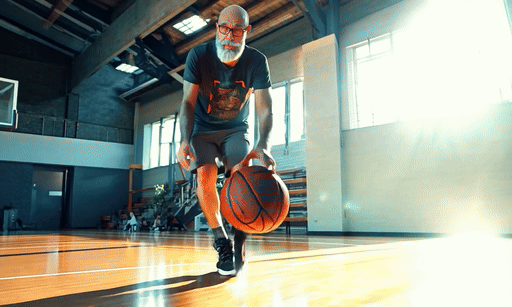
Overall, Gen-3 image-to-video worked incredibly well. Its understanding of motion was as close to realistic as I've seen and one video, where the character is giving a talk at a conference made me do a double take it was so close to real.
Gen-3 is still in Alpha and there will be continual improvements before its general release. We haven't even seen video-to-video yet and it is already generating near-real video.
I love how natural the camera motion feels, and the fact it seems to have solved some of the human movement issues, especially when you start with an image.
Other models put the characters in slow motion when they move, including previous versions of Runway. This solves some of that problem.