
One of the key aims of UALink is enabling a competitive connectivity ecosystem for AI accelerators that will rival Nvidia's established NVLink technology that enables the green company to build rack scale AI-optimized solutions, such as Blackwell NVL72. With the emergence of UALink 1.0, companies like AMD, Broadcom, Google, and Intel will also be able to build similar solutions, using industry-standard technologies rather than Nvidia's proprietary solutions, which means lower costs.
The Ultra Accelerator Link Consortium on Tuesday officially published the final UALink 1.0 specification, which means that members of the group can now proceed with tape outs of actual chips supporting the new technology. The new interconnect technology targets AI and HPC accelerators and is supported by a broad set of industry players — including AMD, Apple, Broadcom, and Intel. It promises to become the de facto standard for connecting such hardware.
The UALink 1.0 specification defines a high-speed, low-latency interconnect for accelerators, supporting a maximum bidirectional data rate of 200 GT/s per lane with signaling at 212.5 GT/s to accommodate forward error correction and encoding overhead. UALinks can be configured as x1, x2, or x4, with a four-lane link achieving up to 800 GT/s in both transmit and receive directions.
One UALink system supports up to 1,024 accelerators (GPUs or other) connected through UALink Switches that assign one port per accelerator and a 10-bit unique identifier for precise routing. UALink cable lengths are optimized for <4 meters, enabling <1 µs round-trip latency with 64B/640B payloads. The links support deterministic performance across one to four racks.
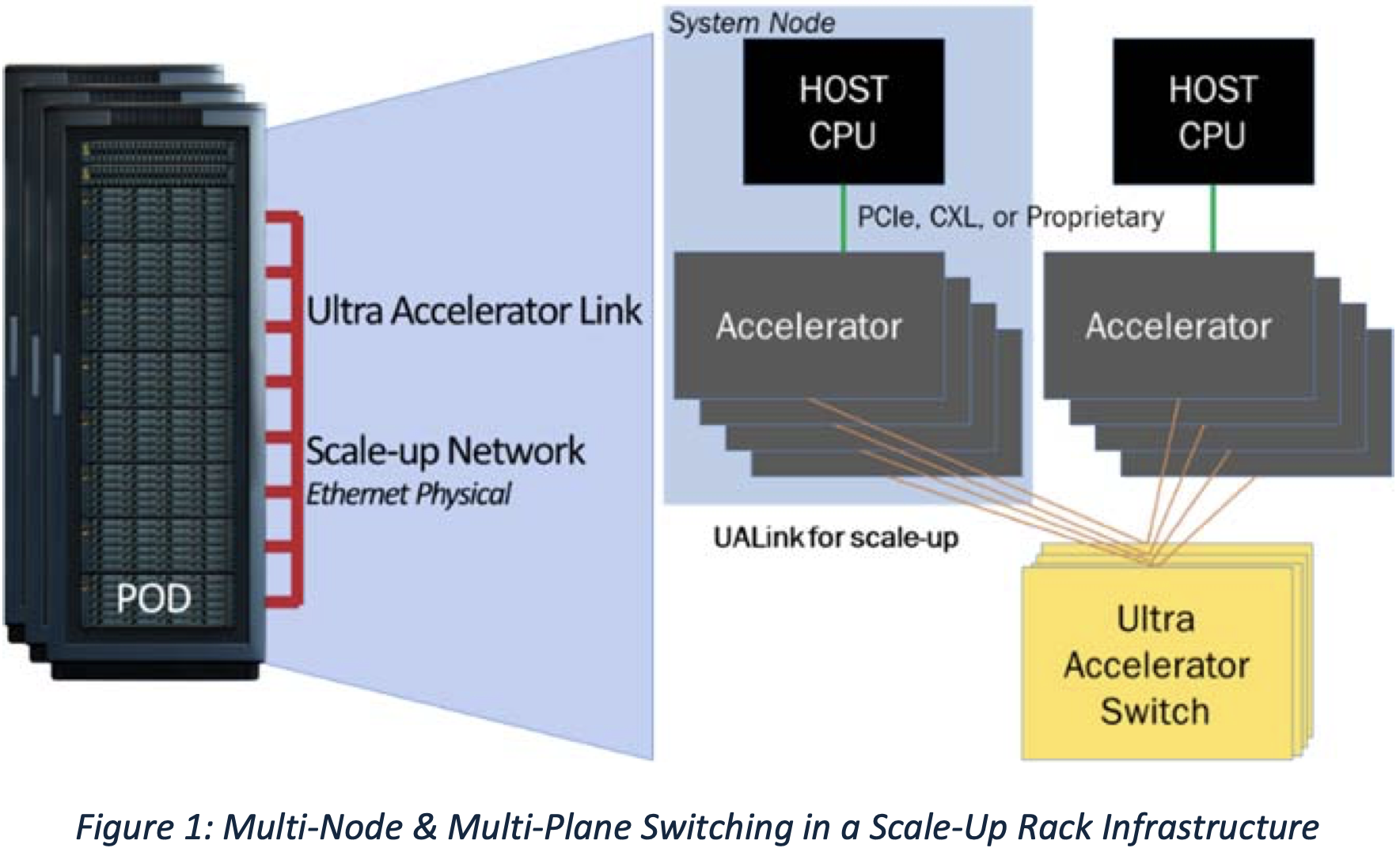
The UALink protocol stack includes four hardware-optimized layers: physical, data link, transaction, and protocol. The Physical Layer uses standard Ethernet components (e.g., 200GBASE-KR1/CR1) and includes modifications for reduced latency with FEC. The Data Link Layer packages 64-byte flits from the transaction layer into 640-byte units, applying CRC and optional retry logic. This layer also handles inter-device messaging and supports UART-style firmware communication.
The Transaction Layer implements compressed addressing, streamlining data transfer with up to 95% protocol efficiency under real workloads. It also enables direct memory operations such as read, write, and atomic transactions between accelerators, preserving ordering across local and remote memory spaces.
As it's aimed at modern data centers, the UALink protocol supports integrated security and management capabilities. For example, UALinkSec provides hardware-level encryption and authentication of all traffic, protecting against physical tampering and supporting Confidential Computing through tenant-controlled Trusted Execution Environments (such as AMD SEV, Arm CCA, and Intel TDX). The specification allows Virtual Pod partitioning, where groups of accelerators are isolated within a single Pod by switch-level configuration to enable concurrent multi-tenant workloads on a shared infrastructure.
UALink Pods will be managed via dedicated control software and firmware agents using standard interfaces like PCIe and Ethernet. Full manageability is supported through REST APIs, telemetry, workload control, and fault isolation.
"With the release of the UALink 200G 1.0 specification, the UALink Consortium's member companies are actively building an open ecosystem for scale-up accelerator connectivity," said Peter Onufryk, UALink Consortium President. "We are excited to witness the variety of solutions that will soon be entering the market and enabling future AI applications."
Nvidia currently dominates in the AI accelerator market, thanks to its robust ecosystem and scale-up solutions. It's currently shipping Blackwell NVL72 racks that use NVLink to connect up to 72 GPUs in a single rack, with inter-rack pods allowing for up to 576 Blackwell B200 GPUs in a single pod. With its upcoming Vera Rubin platform next year, Nvidia intends to scale up to 144 GPUs in a single rack, while Rubin Ultra in 2027 will scale up to 576 GPUs in a single rack.







