
AI is making a big impact in all kinds of sectors at the moment. In the creative fields, most of the attention (and controversy) has revolved around AI text-to-image generators like DALL-E 2. But there are also tools being developed that work the other way around.
Machine learning software developer Replicate has developed Blip-2, an AI model that can caption images and answer questions about them... sometimes. Just don't take its answers as gospel.
Replicate demonstrates the effectiveness of Blip-2 with some solid examples. Presented with an image of the Golden Gate Bridge and asked what body of what it crosses, the model correctly responds San Francisco Bay. It's also able to tell us that pandas come from China and that Marina Bay Sands is located in Singapore.
All you do is upload an image and click submit if you want a caption, or add a question if you're seeking specific information. It then runs predictions on Nvidia A100 GPU hardware. You can then use question answers as added context to ask more questions. It sounds clever and it has several uses – automatic captioning, sorting and classifying images for archiving, for example. But when it comes to trying to find out something we might not know, its predictions can be very unreliable.
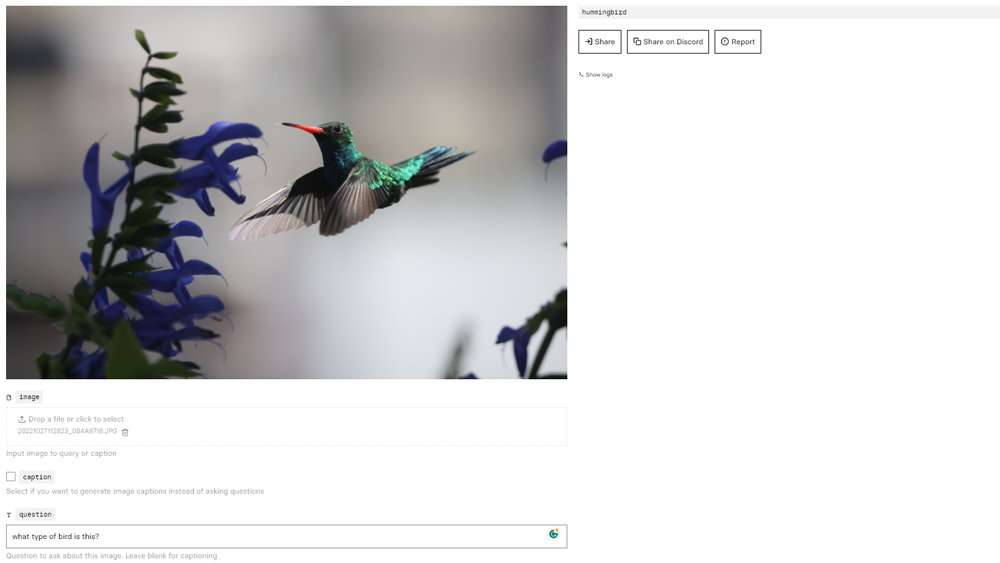
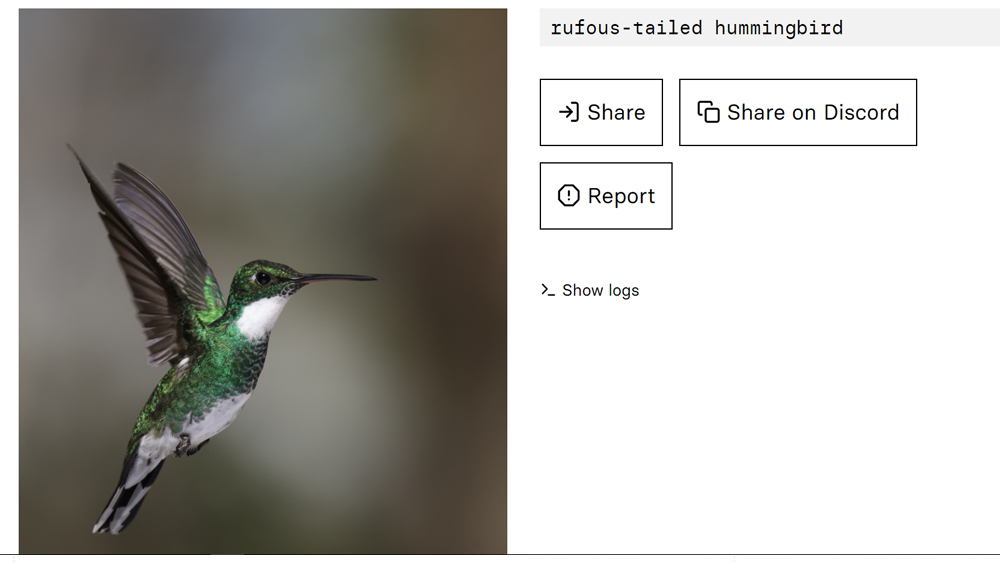
I tested it out by uploading some of my on photos of various kinds of subjects. First up a hummingbird. It gave that the caption: "a hummingbird is flying near some flowers". OK, fine, but that could maybe save me some time if I'm processing a ton of images, but it's not massively informative. I'd like to know what species of hummingbird it is. I ask the question, and it tells me it's a rufous-tailed hummingbird. Only it isn't it's a glittering emerald. I try with another species of bird, and it insists that this species is also a rufous-tailed hummingbird.
OK, so maybe it only got trained on one species of hummingbird. Let's try a mammal. Nobody needs AI to tell them what a panda or an elephant is, so I want to go for something that at least offers a bit of a challenge. A Patagonian mara, say. On the first try, this sends the model into complete fantasy land. It identifies the sleepy rodent as a 'saber-toothed tapir' a species that it seems to have completely made up since there is no reference online to such an animal ever having existed either in reality or fiction.
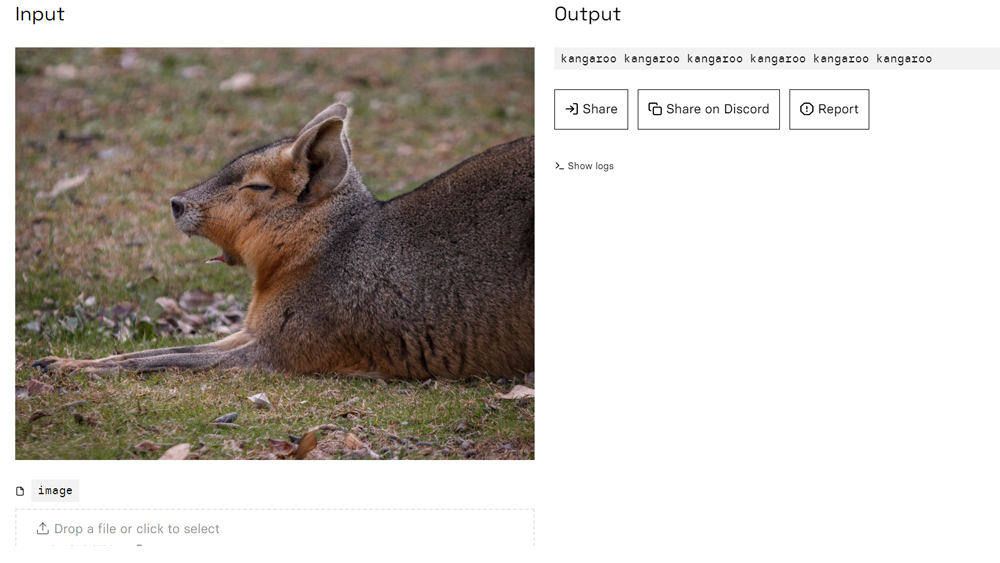
I crop the image closer and try again. This time Blip-2 got excited. It was so convinced it had the answer, that it spat out the word 'kangaroo' several times over. I'll take that to be a 'blip'. OK, well, there are plenty of specialist apps like iNaturalist for identifying animals. Let's try something else.
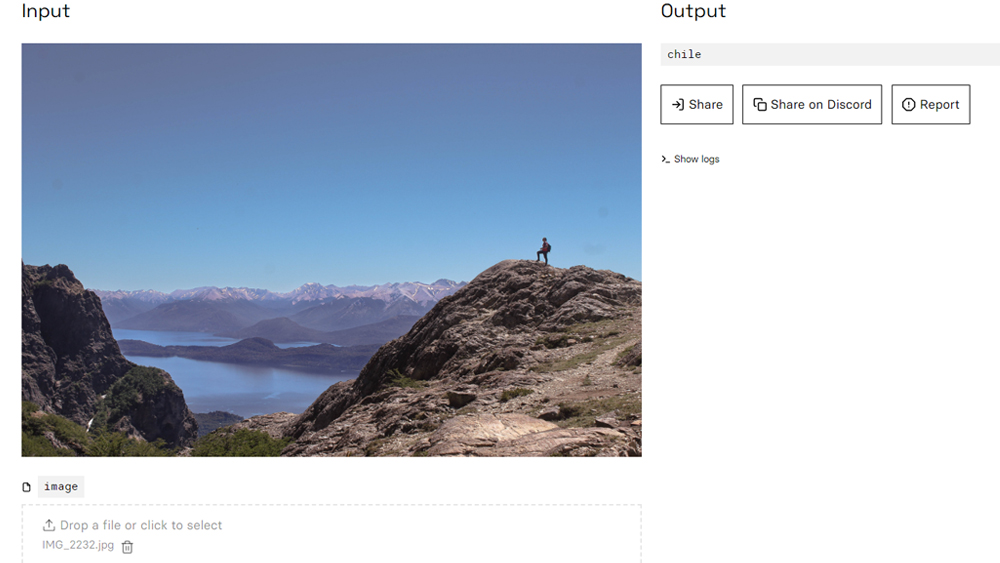
It doesn't do hugely well on buildings, other than things on an Eiffel Tower level of fame. It identified the Kavanagh building, a much-photographed 1930s landmark skyscraper in Buenos Aires, as a nondescript hotel in 'So Paulo' (presumably Sao Paulo) in Brazil. I was, however, impressed that Blip-2 identified a mountain landscape in southwestern Argentina as being in Chile. I mean, that's just over the border and the scenery is comparable. But then 'close-ish" isn't really good enough to be very useful for anything when it comes to captioning an image.
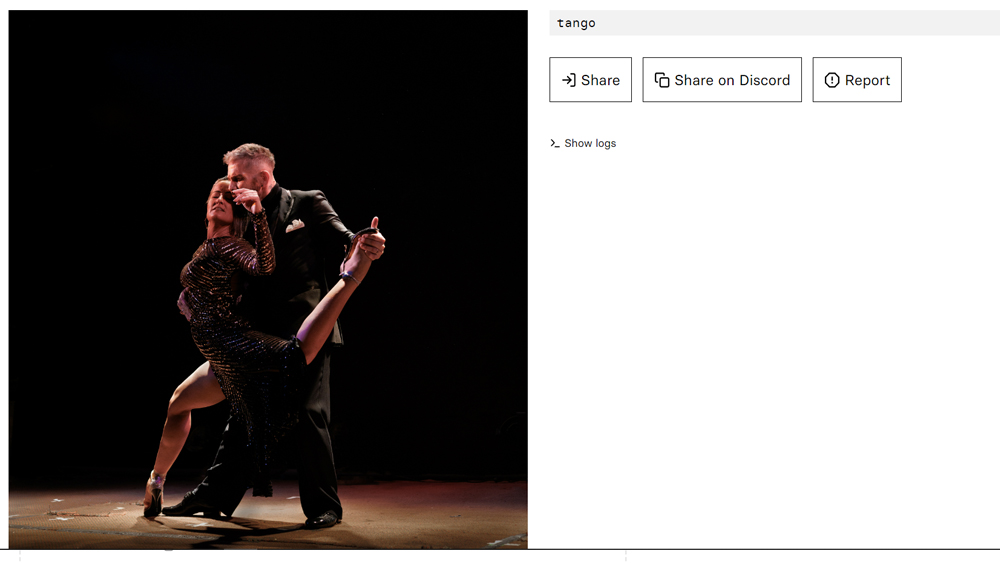
Admittedly, it does better on some images. When asked what dance a couple were dancing, it correctly responded tango. It's also able to identify the logos of major companies, such as TikTok. Captions are also generally accurate if extremely vague. I was disappointed that when fed DALL-E 2's famous astronaut riding a horse, Blip-2 only came up with 'a white horse with a man on it' (although when asked what the man was wearing, it did recognise that he's in a space suit).
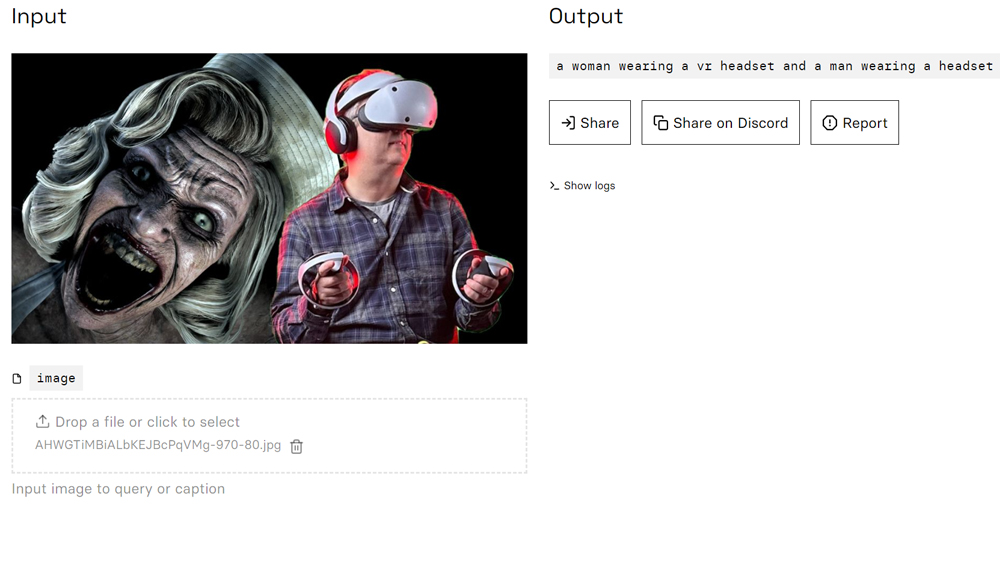

As a final test, I subjected the model to an image of our very own Ian Dean playing Swithback on the PSVR 2. Here it recognised the VR headset but thinks there's two of them. Asked what Ian was playing, it said a VR horror game on PS4, so again kind of on the right track, but not an answer that can be relied on.
Overall, it seems Blip-2 hasn't been trained on enough material to be able to correctly tell s anything that most people don't already know. Yes, pandas live in China and the Golden Gate Bridge is in San Francisco. Anything a little more obscure, and it starts getting creative.
This seems to be one of the problems with AI tools like Blip-2 and the text generator ChatGPT. Rather like some humans, they don't admit it when they don't know something. Instead, they just make it up. That might be fine if the people using them as going to run checks on the output, but if not it could soon become even more difficult to trust online articles, images and now captions.







