
AI chatbots can collapse to the point that they start replying to your questions with gibberish if they’re mainly trained on learning material created by AI, a group of researchers has found.
Ilia Shumailov, a research scientist at Google DeepMind, and his colleagues wanted to find an answer to the question: "What would happen to ChatGPT if the majority of the text it trained on was created by AI?"
The authors explained that as newer LLMs emerge if their training data comes from the internet, they will inevitably be training on data that could have been produced by their older models.
In a paper published in the journal Nature on Wednesday, the researchers found that when LLMs indiscriminately learn from data produced by other models, those LLMs collapse.
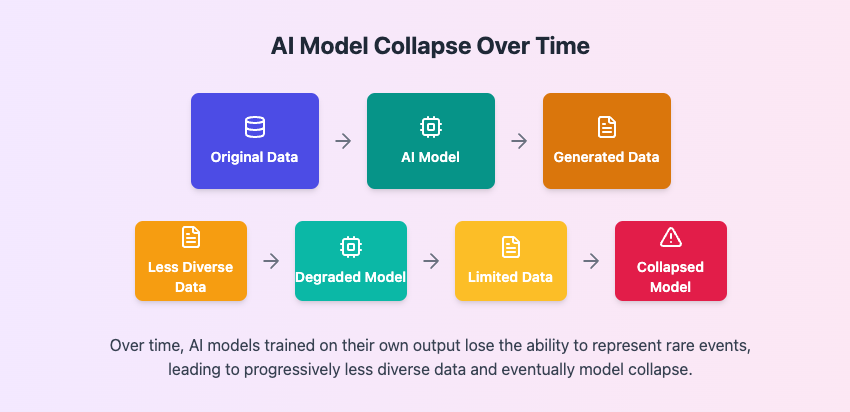
They describe this phenomenon as “model collapse”, a degenerative process where the data generated by one LLM pollutes the training set of the next generation of LLMs. AI models that train on this polluted data end up misperceiving reality.
What happens to the models?
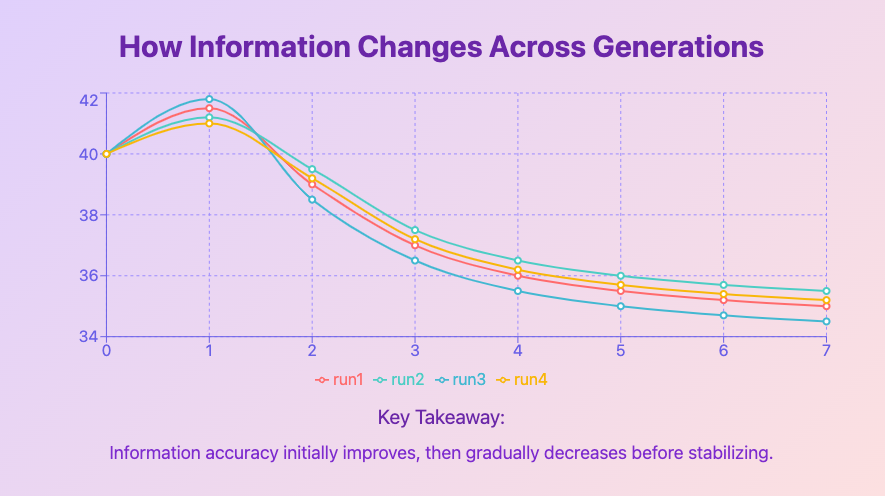
In their experiments, they found that as the models collapsed they resorted to generating repeating phrases. In one example, by the 9th time a model was trained, where each new generation of the model was trained on data produced by the previous one, most of the answers consisted of the phrase “tailed jackrabbits”.
To rule out whether this phrase repetition was what was driving the models to collapse, the researchers even repeated the experiment after encouraging the models to avoid this behavior. The models ended up performing even worse.
It turned out that model collapse happens because when models train on their own data, they ‘forget’ the less-common elements of their original training data set. For example, if a model was asked to generate images of tourist landmarks, it may gravitate towards generating the more popular ones.
If it trains on landmarks it generates itself, those popular landmarks will end up being over-represented to the point that the model only starts generating the Statue of Liberty for example. As this process goes on, eventually, the model collapses.
Should I be worried?
If you’re an average user of AI chatbots you’re unlikely to be affected for now, Shumailov told Tom’s Guide. This is because the main chatbot creators run thorough evaluations that should raise a red flag when their models are degrading, suggesting that an earlier model checkpoint should be used instead.
This phenomenon is also not exactly new, as the researchers pointed out. They highlighted how search engines had to alter the way they rank results after content farms were flooding the internet with low-quality articles. On the other hand, LLMs drastically increase the scale at which such “poisoning” can happen.
The main impact is likely to be that the advancements of machine learning may slow down, since training data will become noisier.
Ilia Shumailov
Nonetheless, the first warning sign of model collapse would be that a chatbot’s performance on unpopular tasks may decrease. As the model continues to collapse, it will start propagating its own errors, which introduces factually incorrect statements, Shumailov said.
“The main impact is likely to be that the advancements of machine learning may slow down, since training data will become noisier,” Shumailov said.
On the other hand, if you’re running an AI company then you’re likely going to want to know more about model collapse as the researchers argue that it can happen to any LLM.
“Since model collapse is a general statistical phenomenon it affects all models in the same way. The effect will mostly depend on the choice of model architecture, learning process, and the data provided,” Shumailov told Tom’s Guide
Reddit to the rescue?
While the researchers say that training LLMs on AI-generated data is not impossible, the filtering of that data has to be taken seriously. Companies that use human-generated content may be able to train AI models that are better than those of their competitors.
Therefore this research shows how helpful platforms such as Reddit, where humans are generating content for other humans, can be for companies like Google and OpenAI – both of which struck deals with the online forum.






