The new Nvidia Blackwell GPU architecture will power the upcoming generation of RTX 50-series GPUs. We've known various details for a while now, and many have been rumored, but at its Editors' Day during CES 2025, Nvidia provided a lot more information and details on the core functionality. There's so much to cover, with seven sessions that took all day, plus some live hands-on experiences.
This article deals primarily with the architectural changes in Blackwell RTX 50-series GPUs. We also have a neural rendering and DLSS 4 deep dive, the RTX 50-series Founders Edition cards, RTX AI PCs and generative AI for games, Blackwell for professionals and creators, and Blackwell benchmarking 101. Let's get to it.


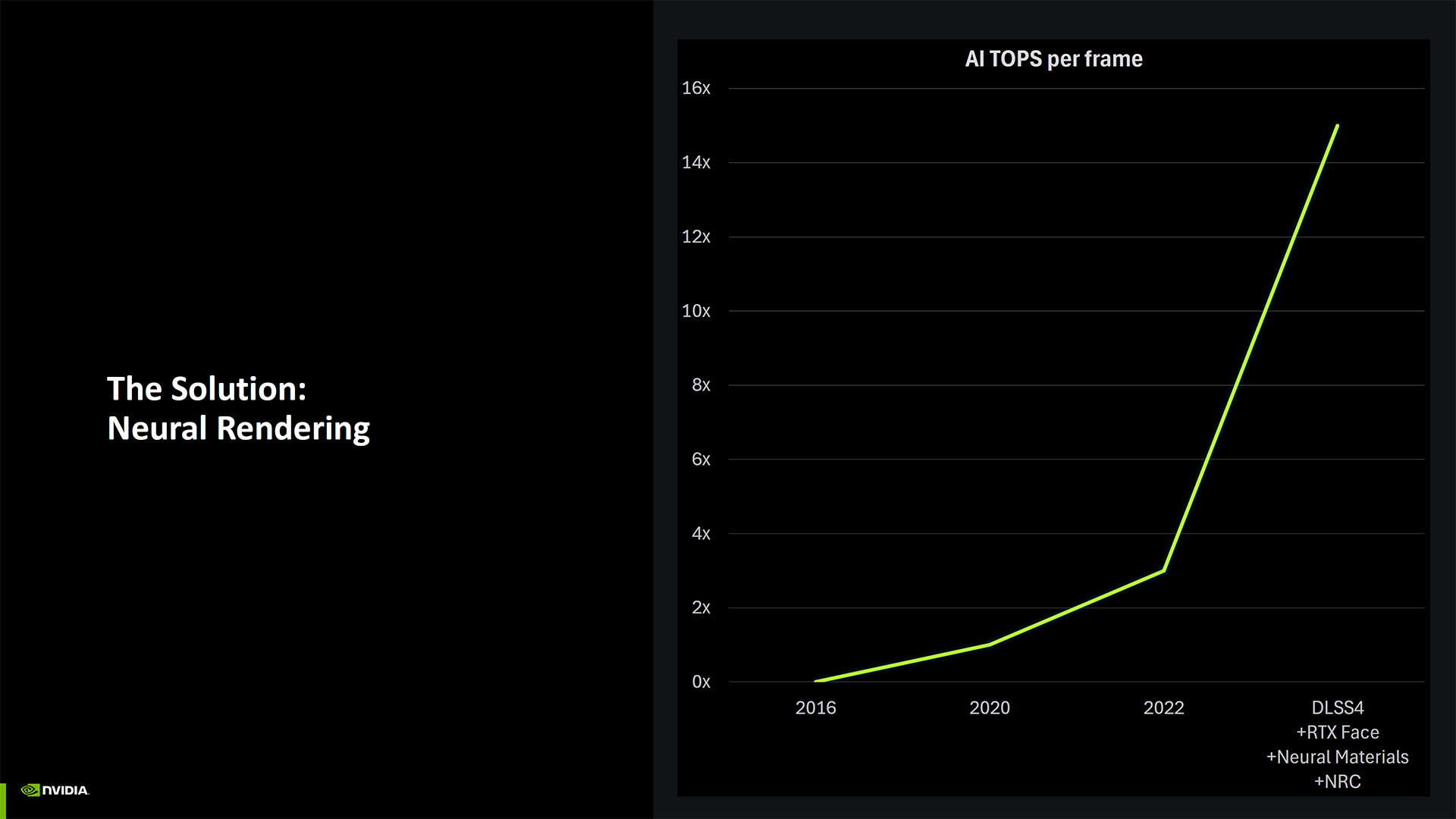

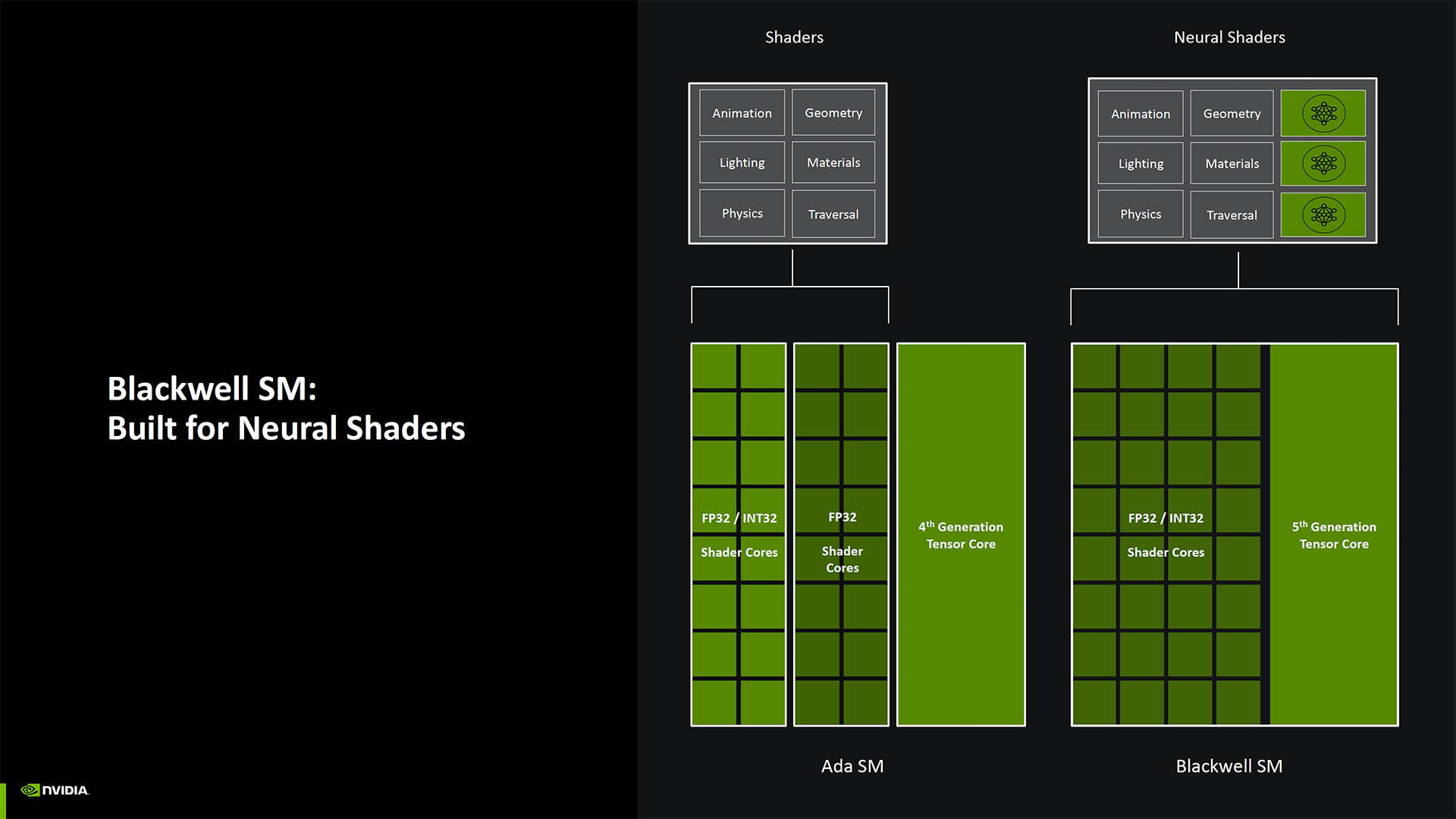





Here's the full slide deck for the Blackwell architecture session. It's... not nearly as long as you might have expected. Nvidia didn't provide a ton of detail on some aspects of the new architecture, but from a high level, there are a lot of things that don't seem to have changed too much from the RTX 40-series Ada Lovelace architecture. Most of the upgrades and enhancements tend to be around AI and various neural rendering technologies — we have a far more in-depth look at those in a separate article.
The fourth slide gives the goals for Blackwell: Optimize for new neural workloads, reduce memory footprint, new quality of service capabilities, and energy efficiency. Those all sound like good things, but outside of the RTX 5090 with its significantly larger GPU die — 744 mm2 compared to 608 mm2 on the 4090 — a lot of the upgrades feel more incremental.
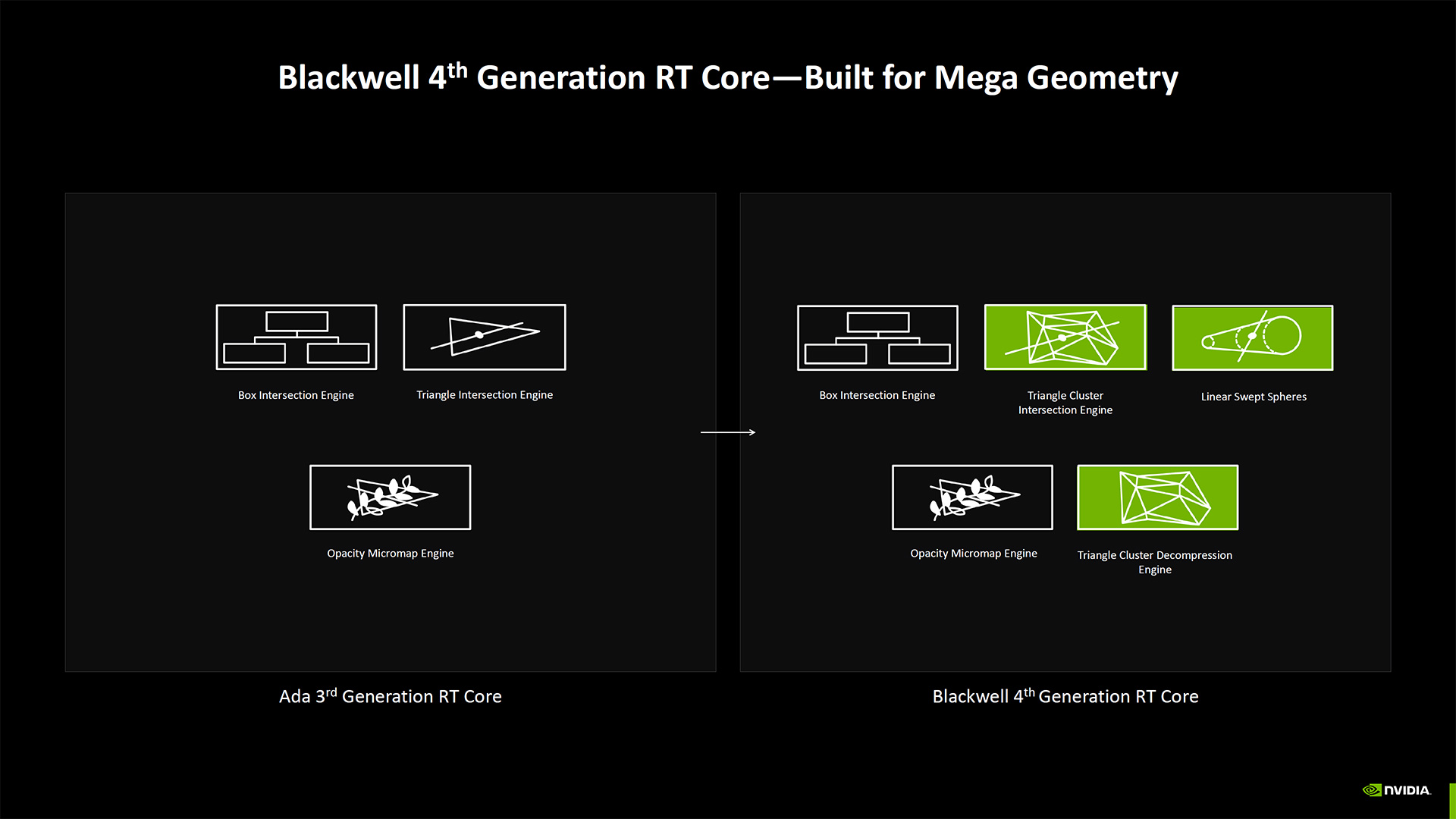
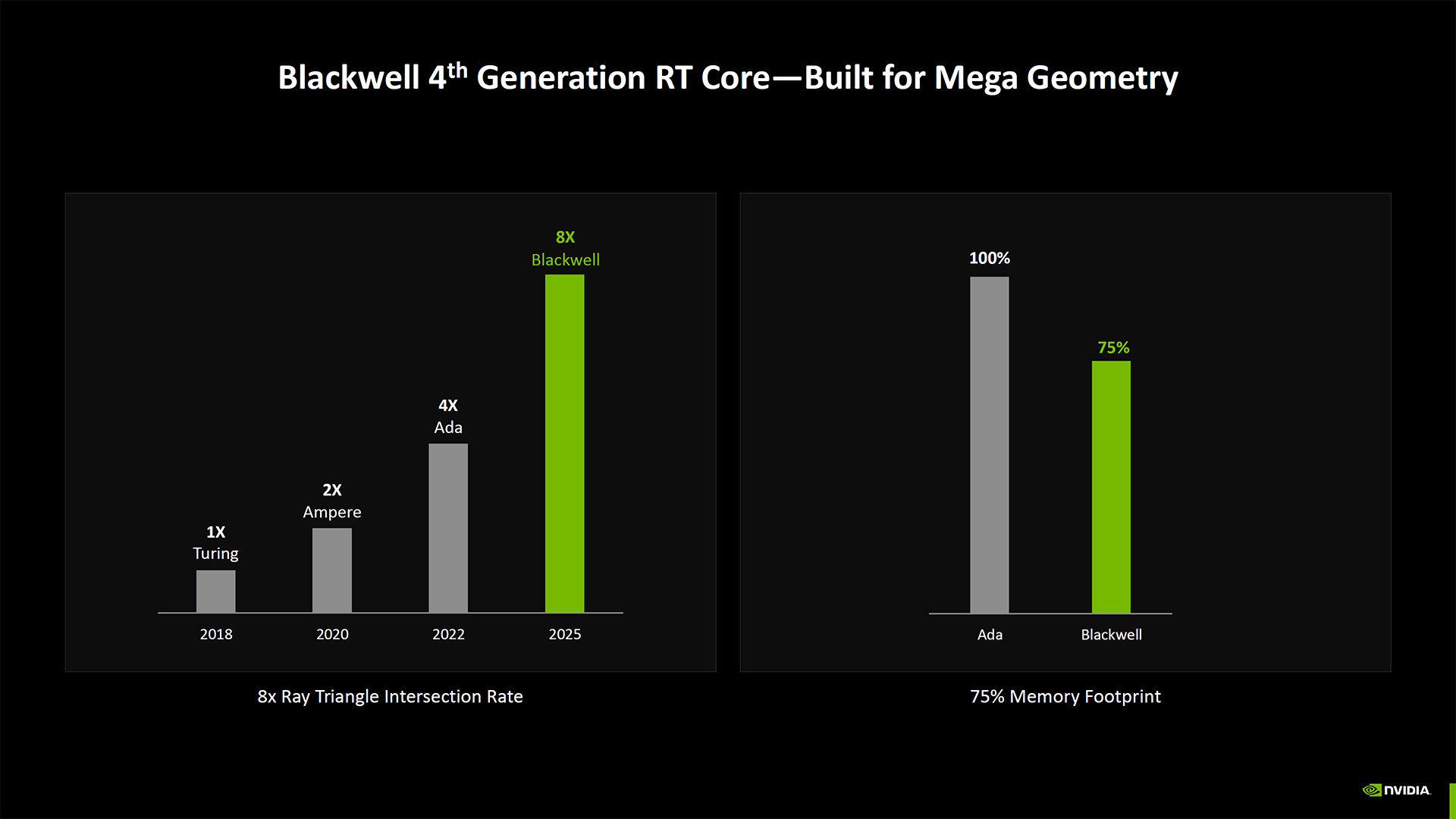
That's not to say things haven't changed at all. The 4th-Gen RT cores have twice the ray triangle intersect rates as Ada. They're also built for Mega Geometry, which could help future Unreal Engine 5 games run better. The GPU shaders are also enhanced for Neural Shaders, and there are some other new additions.
Blackwell will be the first series of Nvidia GPUs to move beyond DisplayPort 1.4a, with full support for DisplayPort 2.1 UHBR20 (80 Gbps). They'll also support PCIe 5.0, the first consumer GPUs to make that transition, though we'll have to see if that applies to all Blackwell GPUs or only the RTX 5090. Video encoding and decoding have been enhanced as well, now with support for 4:2:2 video streams.
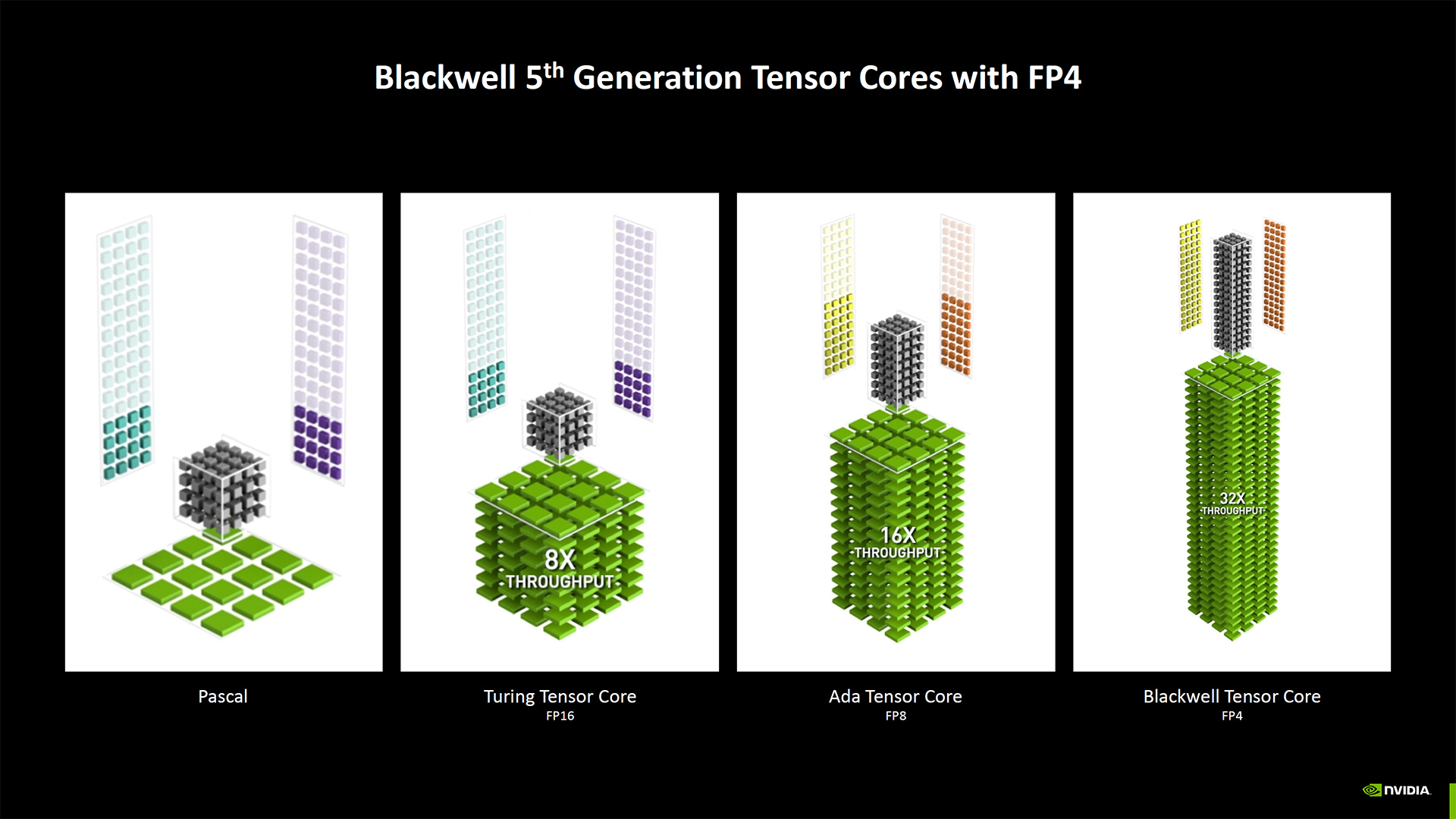
Getting back to the numbers, if you take the "up to 4,000 AI TOPS" (trillions of operations per second), that scales down to 3,400 TOPS on the 5090 (3352, to be precise). Then, you will discover that a big part of the boost comes from native FP4 support. S,o if you compare like-for-like, the RTX 5090 has 1,676 TFLOPS of FP8, whereas the RTX 4090 offers 1,321 TFLOPS FP8. That's only a 27% increase — still sizeable but not massive.
Similar scaling applies elsewhere, like in the FP32 shader compute. The 5090 delivers up to 104.8 TFLOPS of FP32, compared to 82.6 TFLOPS on the RTX 4090. Again, that's a 27% improvement. Let's put that in perspective. The RTX 4090 delivered a whomping 132% increase in GPU TFLOPS compared to the RTX 3090. Now that was an upgrade to get excited about!
The 5090 will no doubt be faster and better than the 4090, but it's not going to completely destroy the prior generation — at least not unless you want to factor in Multi Frame Generation, which we're far less enamored with than Nvidia's marketing department. Incidentally, the 5090 die is also 22% larger, with 21% more transistors, on the same TSMC 4N process node.
Architecturally, there are some other noteworthy changes. With the rise in the use of AI and integer use for such workloads, Nvidia has made all of the shader cores in Blackwell fully FP32/INT32 compatible. So in Ampere (RTX 30-series), Nvidia doubled the number of FP32 CUDA cores but half were only for FP32 while the other half could do FP32 and INT32 — INT32 often gets used for memory pointer calculations. Ada kept that the same, and now Blackwell makes all the CUDA cores uniform again, just with twice as many as in Turing.
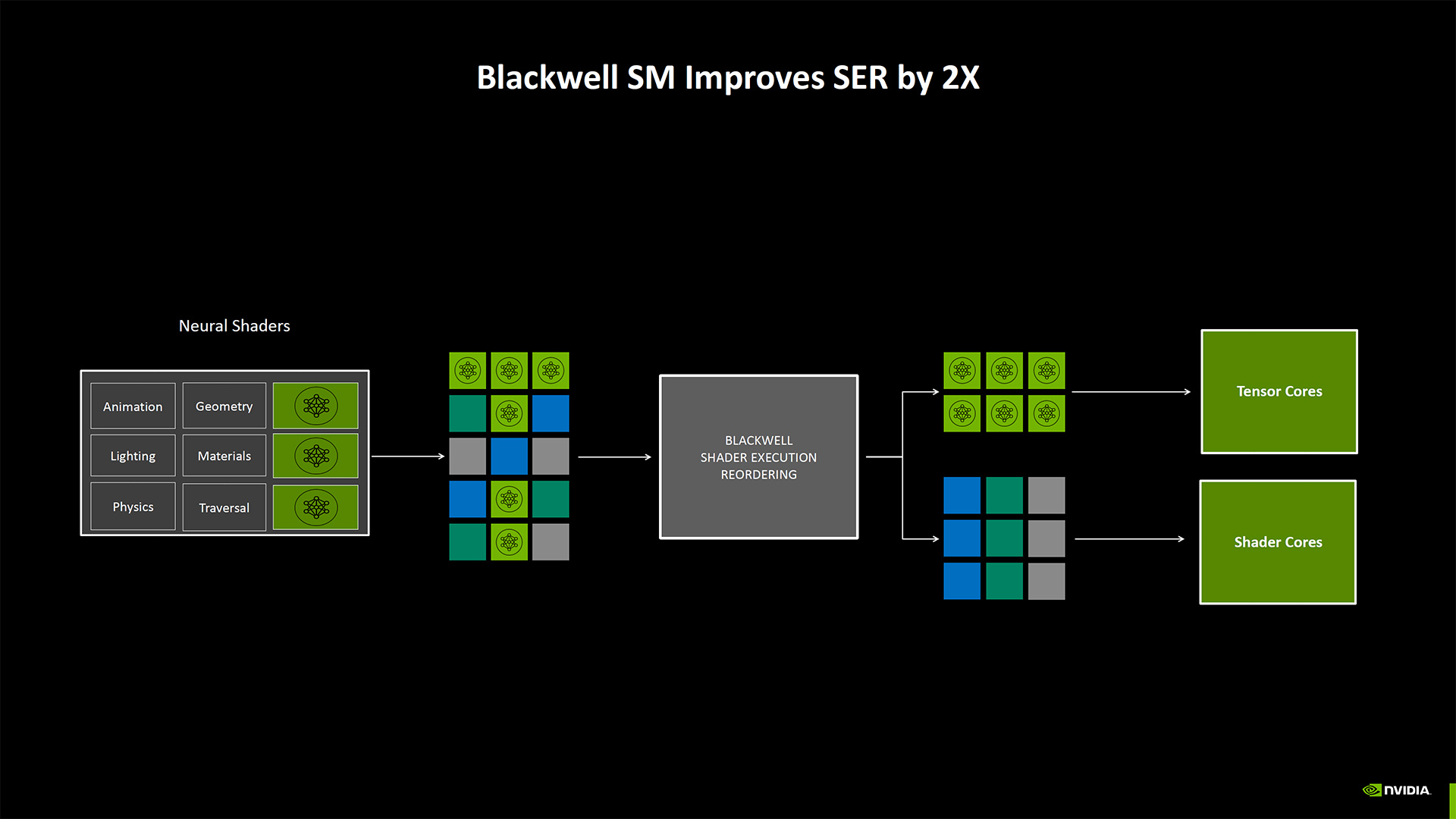
Nvidia also changed some things in the shader rendering pipelines to allow better intermixing of shader and tensor core operations. It classifies this as Neural Shaders, and while it sounds as though other RTX generations can still run these workloads, they'll be proportionally slower than Blackwell GPUs. This appears to be partly thanks to improvements to SER (Shader Execution Reordering), which is twice as fast on Blackwell as on Ada.
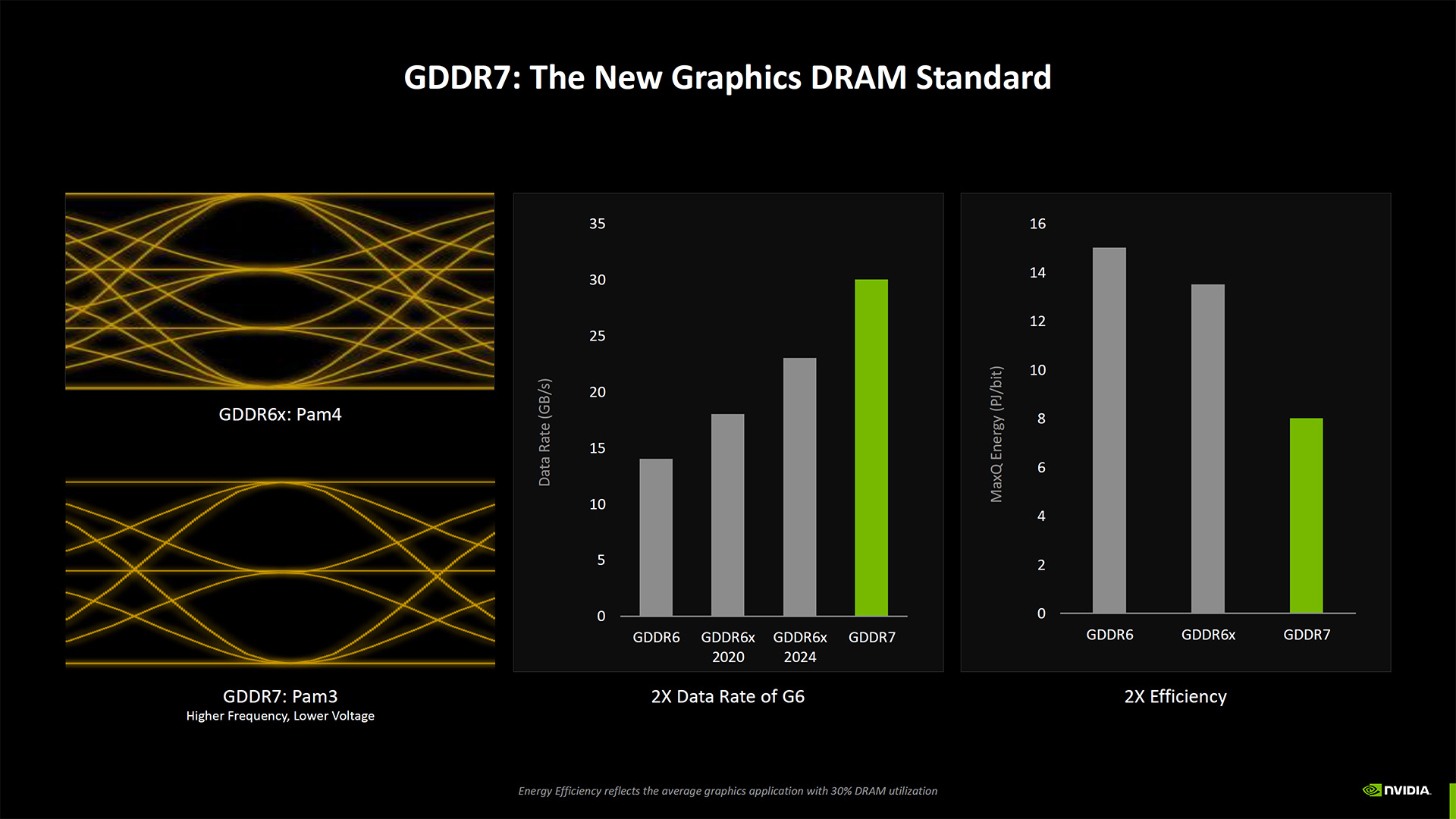
Blackwell also gets a memory upgrade, moving from GDDR6 and GDDR6X on the Ada generation to full GDDR7. We don't know if that will apply to all RTX 50-series GPUs, but considering even the RTX 5070 laptop GPU has 8GB of GDDR7, we assume it's universal. This is the first full shift we've seen in graphics memory since the RTX 20-series back in 2018 first introduced GDDR6 — clocked at just 14 Gbps.
Most of the Blackwell RTX 50-series GPUs will run GDDR7 at 28 Gbps, twice as fast as the original GDDR6 chips, but only 33% faster than the 21 Gbps GDDR6X chips used in many of the higher-spec RTX 40-series GPUs. The RTX 5080 gets a speed bump to 30 Gbps GDDR7, almost twice as fast as the 2080 Super's 15.5 Gbps memory.
Memory interface widths aren't changing, except on the RTX 5090. That will get a huge 512-bit interface with 32GB of GDDR7 memory at launch. Future 3GB GDDR6 chips leave the door open for a potential 48GB update later in the product cycle or for professional / data center GPUs with up to 96GB in clamshell mode, but Nvidia won't officially comment on or announce such things for a while.
The RTX 5080 still has a 256-bit interface and 16GB, so while it gets 30% more bandwidth than the RTX 4080 Super, capacity remains unchanged. The same goes for the 5070 Ti (vs. 5070 Ti Super) and the 5070 (vs. 4070), except they get 33% more bandwidth — 28 Gbps vs. 21 Gbps.
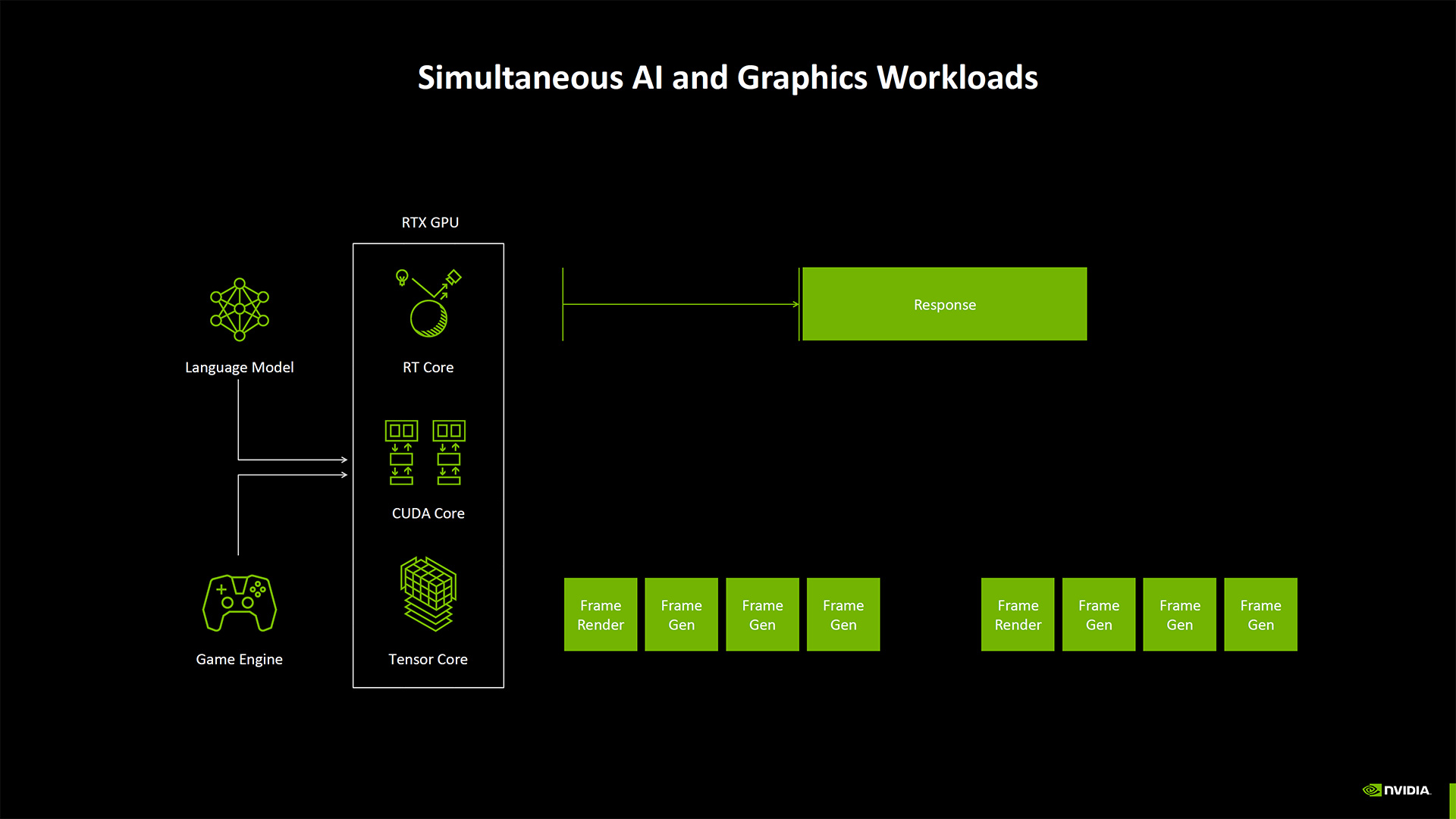
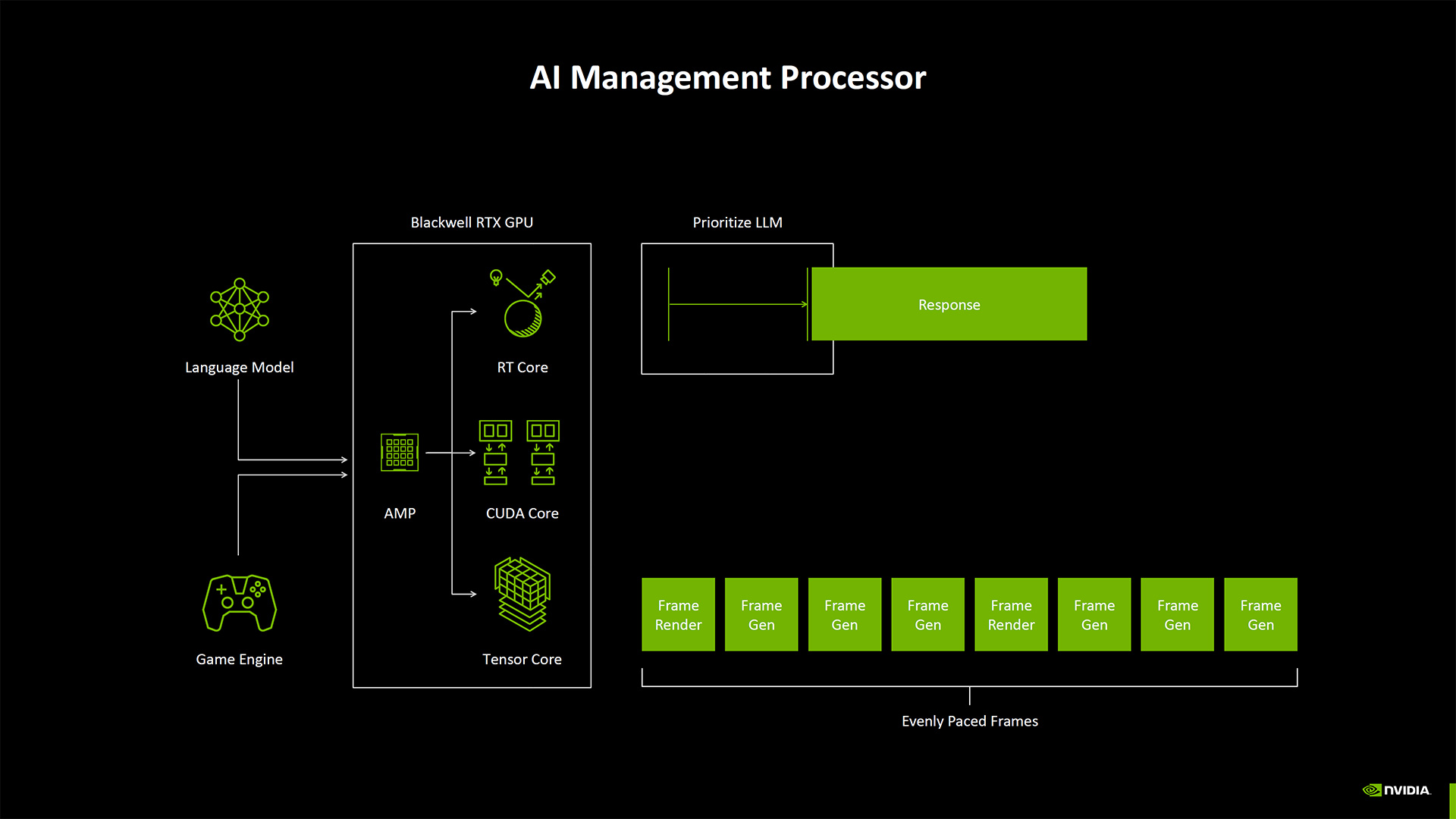
Another new feature of the Blackwell architecture is the AI Management Processor. (And a quick side note here that Nvidia made no mention at all of an Optical Flow Accelerator, aka OFA, which was new for the Ada generation but may now be discontinued and replaced by more potent tensor operations.)
With the increasing complexity of AI workloads, and the potential for more AI models running concurrently — imagine a game doing upscaling, neural textures, frame generation, and AI NPCs — Nvidia wanted better scheduling of resources. The AI Management Processor aims to do that and can apparently be given hints of what sort of workload is running and which needs to be finished first. So, an LLM doing text generation might be okay to delay slightly in order to get MFG (Multi Frame Generation) done first.
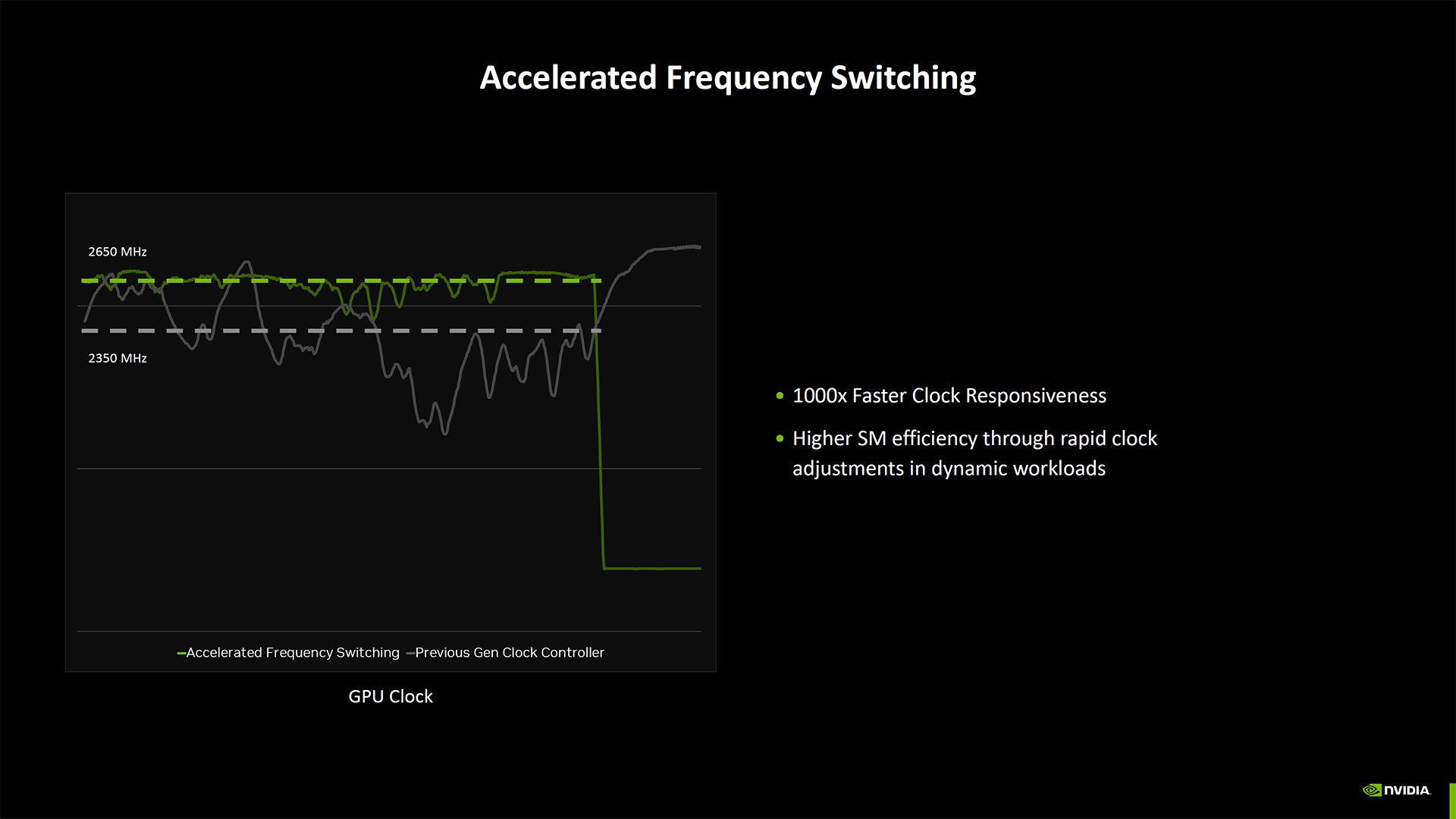
Blackwell also comes with improvements to power gating and energy management, with the ability to enter and exit deeper sleep modes more quickly than prior generations.
And that does it for the Blackwell architecture deep dive. Admittedly, a lot of this stuff was covered in more detail in some of the other sessions, like the Neural Rendering and AI portions. Check the full slide deck at the top for additional details.