
The dream of having a robot make you breakfast, take over your chores or do more than your typical robot vacuum could be a step closer thanks to new research from Google’s AI-lab DeepMind.
Three new research papers from DeepMind covering automation, reaction times, and motion tracking in robots allow them to work more efficiently in the real world.
The techniques allow the robots to use powerful large language models, such as the one powering ChatGPT, to learn about and understand complex tasks without having to be trained from scratch for each new function.
Giving robots a brain and a constitution

In a series of videos showing the potential of the research, the robots can be seen picking up soda cans, opening and closing drawers and even cleaning a surface.
Previously, each of the parts of those tasks would have required lines of code and specific training. The new research allows the bots to learn by watching, examining the environment and working out the task themselves in real-time.
There is also a new robot constitution that sets out safety rules for both the bots and the underlying large language model decision-making system. Based on Isaac Asimov's famous three laws of robotics, they essentially say do no harm to humans.
AutoRT gives vision to robots
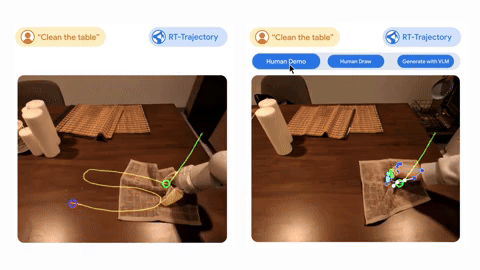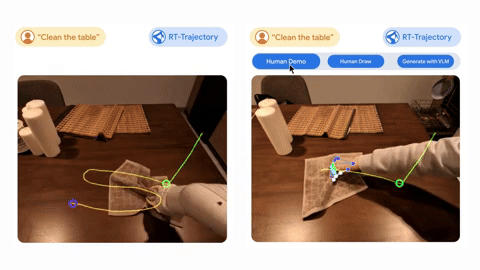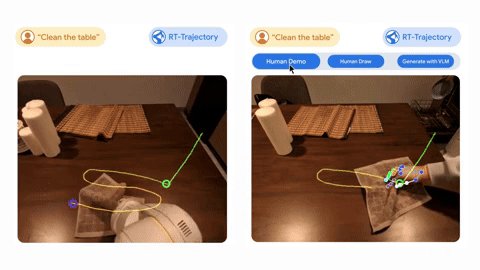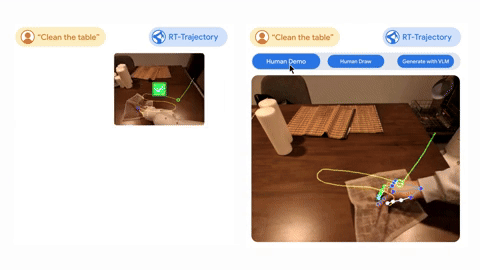
The first of the new technologies is AutoRT, a technique that teaches multiple robots at once to perform different tasks in a range of environments at the same time.
They use a visual language model to study the environment and objects and feed that data into a large language model. This model acts as the decision maker for the bot and tells it which task it should perform next and how to perform that task.
This system was tested over seven months and used to train 20 robots. In total they performed 6,650 individual tasks during the training period to fine-tune the data collection and processing.
SARA lets the robots make changes themselves

Self-Adaptive Robust Attention for Robotics Transformers (or SARA-RT for short) is a new system that is scalable and lets the robots make improvements to their instructions based on real-world feedback. It is a way of fine-tuning the model to work as efficiently as possible.
The robot can take in spatial data from its cameras, and information from other sensors and use that to pick the best path to completion for any given task.
The final technique provides visual contour data for robots that can add descriptions to the training data. It can use this additional data to generalize more effectively and improve its understanding of the task it has to perform.
This is just an early research project from DeepMind, working on the underlying technology rather than deploying it to live products. So don’t expect an android to make you a coffee anytime soon.







