-4.jpg)
Image: Zamrznuti tonovi | Shutterstock
As technical ecosystems stretch across more layers and systems, platform teams are becoming key players in delivering end-to-end business outcomes.
Yet, the term “full-stack ownership” is often used without a clear definition, especially in platform contexts. That confusion slows teams down, leading to inefficiency and stalled progress.
At LinkedIn, where I lead engineering teams building infrastructure for advertisers and enterprise customers, I’ve seen how full-stack accountability changes the pace and quality of delivery.
Teams that take ownership across layers—from the UI to backend services to data pipelines—ship faster, recover more quickly, and stay aligned with user needs. Those who don’t struggle to move beyond internal blockers and scattered priorities.
This article breaks down what full-stack ownership really means in platform contexts, offers practical approaches to making it work, and outlines why this mindset is essential for engineering teams operating in AdTech, SaaS, or complex B2B systems.
Key Concepts: Understanding Full-Stack Ownership in Platform Teams
The term “full-stack” often brings to mind solo developers building simple CRUD (Create, Read, Update, Delete) apps. However, full-stack in platform engineering is far broader. It involves end-to-end responsibility over complex integrated systems, including:
- UX Workflows: Building intuitive interfaces aligned with user needs, even for internal tools.
- Backend APIs: Designing scalable services that connect frontend, logic, and data systems.
- Real-Time Data Pipelines: Streaming and processing data for analytics or live features.
- Observability: Implementing logs, metrics, and tracing to monitor and maintain reliability.
- Experimentation Hooks: Enabling A/B tests and feature flags to validate changes safely.
Think of platform systems as structured layers: frontend behavior is only as good as the backend APIs it relies on, which in turn depend on data reliability and event propagation. Full-stack ownership makes sure these connections are intentional and maintainable, leading to fewer issues and faster feedback loops.
Modern frameworks like Next.js and Nuxt make this model more approachable. These tools collapse the divide between frontend and backend concerns, letting teams iterate with less overhead. That speed is essential when you're supporting evolving internal and external use cases across large codebases.

Source: The evolution of full-stack development with AWS Amplify | AWS
Still, no one expects every engineer to master every layer. High-performing teams grow T-shaped engineers—those with deep expertise in one domain and working context in others. This leads to better design, stronger communication, and quicker incident recovery.
With better tools, collaborative habits, and a more grounded view of full-stack responsibility, the conversation shifts from what it is to why it matters.
Why Full-Stack Ownership Matters: Avoiding Fragmentation and Promoting Holistic Thinking
Full-stack ownership changes how platform teams operate—not just by speeding up delivery, but by transforming how engineers understand and influence the systems they build.
Streamlined Delivery and Agility through Unified Ownership
Traditional workflows rely on handoffs: frontend teams wait on backend teams, backend teams wait on data teams, and blockers mount. This slows everything down. With full-stack ownership, a single team is equipped to build, test, and ship features end-to-end, cutting the waiting and improving clarity.
These teams ship faster and troubleshoot more efficiently because they understand how each part of the stack behaves. Instead of stopping at the edge of their domain, engineers can follow problems through the entire system. That autonomy becomes especially valuable in platform settings, where internal customers—marketing, analytics, operations—need responsive iteration, not long lead times.
Deepened Empathy and Elevated Product Quality
Full-stack ownership is also about insight. Engineers who engage across UX, services, and data layers build a more complete mental model of how users experience the product. This holistic awareness leads to better architectural decisions, more resilient systems, and a stronger alignment with customer needs.
At LinkedIn, this shift helped us improve campaign management for advertisers. By embedding engineers into every part of the stack—and encouraging tight collaboration with product and sales—we uncovered key friction points. One result was the Boost feature, which let organic users promote content directly with minimal overhead. It delivered a better experience and became a meaningful driver of revenue.
“The boost feature was straightforward to use. For us, that means we could take a post that was doing well and just push it out further without any additional effort.”
— Charly Buesnel, Digital Executive at Crestbridge
Addressing Common Challenges in Full-Stack Ownership
Despite the benefits, full-stack ownership comes with real operational challenges, especially in larger systems with multiple stakeholders.
Knowledge Silos
In many engineering organizations, deep specialization in frontend, backend, or data systems can lead to isolated workflows and fragmented context. Teams focused on just one part of the system lose visibility into how their work affects the whole. Silos is often the single biggest obstacle to delivering on the promise of digital transformation, blocking the communication and coordination needed for cross-functional execution.
Reliability vs. Velocity Tension
Teams under pressure to ship quickly often trade off on system stability. This tension is amplified in environments with distributed systems, multiple dependencies, and asynchronous release cycles. Without clear priorities and shared ownership, reliability can slip through the cracks.
End-to-End Testing Complexity
Testing full-stack platforms is inherently complex. Verifying UI interactions, API behaviors, backend logic, and data consistency across services requires orchestration and careful coverage. Inconsistent or incomplete test strategies can lead to regressions, degraded user experience, and operational overhead.
Limited Observability Across the Stack
Full ownership demands visibility into how user actions propagate across services. Yet many teams lack cohesive observability, making it difficult to trace issues from frontend events through backend systems and into data pipelines. This fragmentation complicates incident response and erodes confidence in system health.
-3.jpg)
Image: Tapati Rinchumrus | Shutterstock
Practical Strategies for Effective Full-Stack Delivery
Adopting full-stack ownership doesn’t mean every engineer becomes an expert in every system. Instead, it’s about designing practices and culture that support shared accountability.
Cross-Training and Knowledge Sharing
Encouraging engineers to gain proficiency in adjacent stacks—frontend specialists delving into backend APIs, backend engineers understanding data pipelines—promotes collaboration and reduces reliance on singular expertise.
Clear API Contracts and Communication Standards
Standardizing communication via clearly defined API contracts prevents integration issues and encourages seamless collaboration between services. Tools like Swagger and OpenAPI support documentation and version control, reducing misunderstandings and rework.
Leveraging Feature Toggles and Experimentation Frameworks
Feature toggles and experimentation allow controlled deployments, granular rollouts, and safer feature iterations. For instance, LinkedIn’s Ads Campaign Manager platform extensively leverages experimentation to validate new advertiser workflows before full-scale rollouts, minimizing risk.
Monitoring and Observability at Every Layer
Define and track Service Level Indicators (SLIs) across each component—UI latency, API error rates, pipeline freshness—and tie these to Service Level Objectives (SLOs). Below is an example of common SLO metrics:
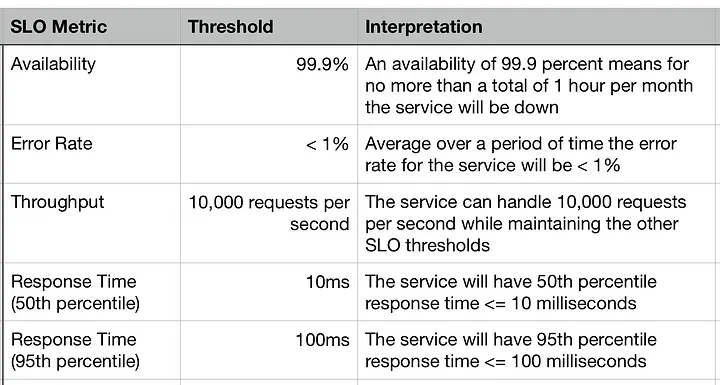
Source: Service Level Objectives (SLI, SLO, SLA) Explained Simply | Medium
This gives teams clarity on when performance degrades—and ensures issues are visible before they become incidents.
Prioritize Documentation and System Diagrams
Architecture diagrams, data flow visuals, and decision records help cross-functional teams understand and maintain complex systems. Invest in documentation platforms that support collaborative, persistent knowledge, not just internal wikis that get ignored.
Sample Use Cases: Applying Full-Stack Ownership in Platform Teams
Here are sample cases of how full-stack ownership can be applied in platform teams, particularly within AdTech, SaaS, and data-driven systems.
1. Building Advertiser Workflows
Platform teams often develop complex workflows, such as campaign setup tools. Engineers are responsible for crafting the frontend UI (e.g., React, Vue.js), implementing backend validation and persistence (e.g., Django, FastAPI), and streaming user inputs to analytics pipelines. Full-stack ownership ensures these layers evolve in sync, reducing rework and enabling faster delivery.
2. Introducing Reporting Metrics
Adding a new metric to dashboards requires coordinated changes across the database, backend APIs, and UI components. By using tools like PostgreSQL for storage and Metabase for visualization, a single team can align definitions, avoid misinterpretations, and ship reliable reporting features faster.
3. Developing Real-Time Monitoring Tools
To surface live system health, teams must ingest logs, process data in real time (e.g., via Kafka and Spark), expose APIs, and render dashboards. Stream processing enables near-instantaneous analysis of continuous data flows, allowing teams to detect issues and respond quickly. Full-stack ownership streamlines this process, enabling rapid iteration and deeper observability across layers.
4. Managing Feature Flags and Experiments
Experimentation requires consistent logic across the frontend, backend, and data tracking. Open-source tools like Unleash, GrowthBook, or Flipt help manage feature flags, while Snowplow or PostHog assist with event tracking. By owning the full flow—from gating logic to instrumentation—teams can safely run experiments and iterate quickly based on measured impact.
Shaping Team Structure and Culture for Full-Stack Success
Full-stack ownership is as much about team culture as it is about architecture. It flourishes in environments that promote autonomy, learning, and shared responsibility. Central to this is the “you build it, you run it” principle, popularized by Google’s SRE (Site Reliability Engineering) model, which encourages engineers to own systems end-to-end—from development to production support. This reduces operational silos and fosters accountability.
Rotating engineers across frontend, backend, and data layers builds T-shaped skill sets—deep in one area, broad enough to collaborate effectively across others. These rotations not only improve empathy between roles but also help prevent bottlenecks and foster innovation.
It also helps to be clear about expectations. Full-stack doesn’t mean being an expert in everything, but having enough context to contribute meaningfully across boundaries. Recognizing cross-functional contributions—through demos, peer kudos, or review cycles—reinforces the behaviors that sustain this culture.
Final Thoughts: Embracing a New Mindset
Adopting full-stack ownership is no longer optional for platform teams aspiring to deliver holistic, impactful results. It has become essential for building reliable, scalable systems that evolve quickly without compromising quality.
When engineers own their systems end-to-end—from UI to backend to data—they deliver with more speed, alignment, and impact. In my experience leading platform teams through high-stakes product launches and multi-layered integrations, the teams that thrived weren’t just technically skilled—they operated with shared context, cared deeply about internal user experience, and took responsibility for every line of code, whether it touched UI or data infrastructure.
Whether you’re managing AdTech, SaaS platforms, or complex B2B systems, now is a good time to rethink how work gets done. Treat platform ownership as a full-stack discipline, and you’ll start seeing sharper decisions, faster delivery, and more meaningful progress.
About the Author:
Devang Negandhi is a Software Engineering Manager at LinkedIn, where he has led full-stack platform initiatives impacting millions of users and generating new revenue streams. He’s passionate about transforming technical complexity into user value and building teams that thrive at the intersection of systems and product.
References:
Wirjo, D., & Hoskyns, F. (2024, May 6). The evolution of full-stack development with AWS Amplify | Amazon Web Services. Amazon Web Services. https://aws.amazon.com/blogs/mobile/evolution-of-full-stack-development-with-aws-amplify/
MongoDB. (2022, June 9). What is full Stack development? | A complete guide | MongoDB. https://www.mongodb.com/resources/basics/full-stack-development
Hutchinson, A. (2021, May 25). LinkedIn Adds New 'Boost' Option for Organic Posts, New Event Promotion and Management Tools. Social Media Today. https://www.socialmediatoday.com/news/linkedin-adds-new-boost-option-for-organic-posts-new-event-promotion-and/600654/
Liolis, S. (2021, June 21). Council Post: You shall not pass: Silos must be broken down for successful digital transformation. Forbes. https://www.forbes.com/councils/forbestechcouncil/2021/06/21/you-shall-not-pass-silos-must-be-broken-down-for-successful-digital-transformation/
Froehlich, S. (2023, April 10). Service level objectives (SLI, SLO, SLA) explained simply. Medium. https://froehlich.medium.com/service-level-objectives-sli-slo-sla-explained-simply-fb4b91dd4a07
Zaman, A. U. (2023, May 7). Kafka with Spark Streaming —Different Approaches to Read Data. Medium. https://medium.com/plumbersofdatascience/kafka-with-spark-streaming-different-approaches-to-read-data-f38616c023b8
Ukis, V. (2023, March 20). Who builds it and who runs it? SRE team topologies. Stack Overflow. https://stackoverflow.blog/2023/03/20/who-builds-it-and-who-runs-it-sre-team-topologies/