
DeepSeek, a Chinese AI startup, says it has trained an AI model comparable to the leading models from heavyweights like OpenAI, Meta, and Anthropic, but at an 11X reduction in the amount of GPU computing, and thus cost. The claims haven't been fully validated yet, but the startling announcement suggests that while US sanctions have impacted the availability of AI hardware in China, clever scientists are working to extract the utmost performance from limited amounts of hardware to reduce the impact of choking off China's supply of AI chips. The company has open-sourced the model and weights, so we can expect testing to emerge soon.
Deepseek trained its DeepSeek-V3 Mixture-of-Experts (MoE) language model with 671 billion parameters using a cluster containing 2,048 Nvidia H800 GPUs in just two months, which means 2.8 million GPU hours, according to its paper. For comparison, it took Meta 11 times more compute power (30.8 million GPU hours) to train its Llama 3 with 405 billion parameters using a cluster containing 16,384 H100 GPUs over the course of 54 days.
DeepSeek claims it has significantly reduced the compute and memory demands typically required for models of this scale using advanced pipeline algorithms, optimized communication framework, and FP8 low-precision computation as well as communication.
The company used a cluster of 2,048 Nvidia H800 GPUs, each equipped with NVLink interconnects for GPU-to-GPU and InfiniBand interconnects for node-to-node communications. In such setups, inter-GPU communications are rather fast, but inter-node communications are not, so optimizations are key to performance and efficiency. While DeepSeek implemented tens of optimization techniques to reduce the compute requirements of its DeepSeek-v3, several key technologies enabled its impressive results.
DeepSeek used the DualPipe algorithm to overlap computation and communication phases within and across forward and backward micro-batches and, therefore, reduced pipeline inefficiencies. In particular, dispatch (routing tokens to experts) and combine (aggregating results) operations were handled in parallel with computation using customized PTX (Parallel Thread Execution) instructions, which means writing low-level, specialized code that is meant to interface with Nvidia CUDA GPUs and optimize their operations. The DualPipe algorithm minimized training bottlenecks, particularly for the cross-node expert parallelism required by the MoE architecture, and this optimization allowed the cluster to process 14.8 trillion tokens during pre-training with near-zero communication overhead, according to DeepSeek.
In addition to implementing DualPipe, DeepSeek restricted each token to a maximum of four nodes to limit the number of nodes involved in communication. This reduced traffic and ensured that communication and computation could overlap effectively.
A critical element in reducing compute and communication requirements was the adoption of low-precision training techniques. DeepSeek employed an FP8 mixed precision framework, enabling faster computation and reduced memory usage without compromising numerical stability. Key operations, such as matrix multiplications, were conducted in FP8, while sensitive components like embeddings and normalization layers retained higher precision (BF16 or FP32) to ensure accuracy. This approach reduced memory requirements while maintaining robust accuracy, with the relative training loss error consistently under 0.25%.
When it comes to performance, the company says the DeepSeek-v3 MoE language model is comparable to or better than GPT-4x, Claude-3.5-Sonnet, and LLlama-3.1, depending on the benchmark. Naturally, we'll have to see that proven with third-party benchmarks. The company has open-sourced the model and weights, so we can expect testing to emerge soon.
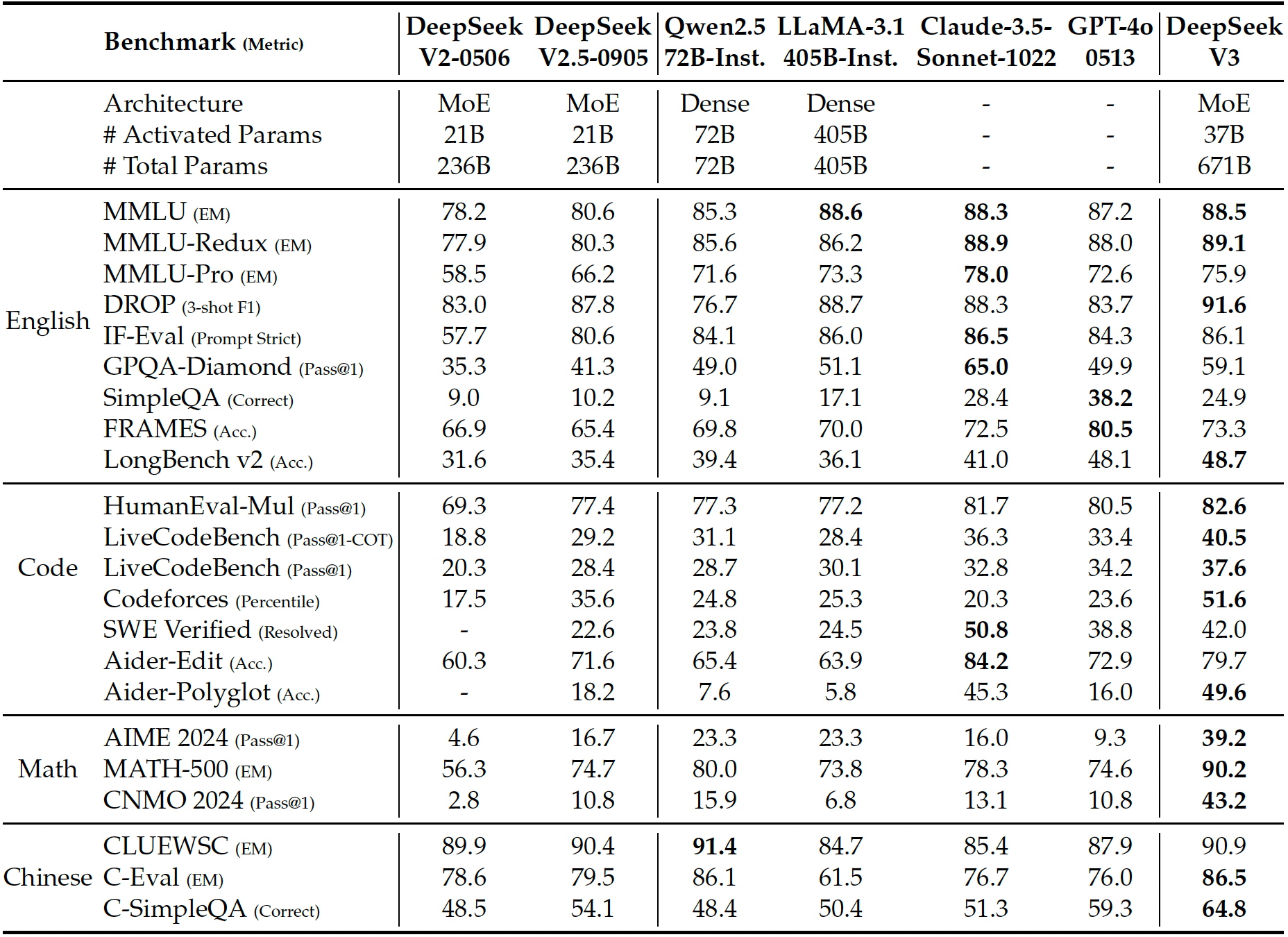
While the DeepSeek-V3 may be behind frontier models like GPT-4o or o3 in terms of the number of parameters or reasoning capabilities, DeepSeek's achievements indicate that it is possible to train an advanced MoE language model using relatively limited resources. Of course, this requires a lot of optimizations and low-level programming, but the results appear to be surprisingly good.
The DeepSeek team recognizes that deploying the DeepSeek-V3 model requires advanced hardware as well as a deployment strategy that separates the prefilling and decoding stages, which might be unachievable for small companies due to a lack of resources.
"While acknowledging its strong performance and cost-effectiveness, we also recognize that DeepSeek-V3 has some limitations, especially on the deployment," the company's paper reads. "Firstly, to ensure efficient inference, the recommended deployment unit for DeepSeek-V3 is relatively large, which might pose a burden for small-sized teams. Secondly, although our deployment strategy for DeepSeek-V3 has achieved an end-to-end generation speed of more than two times that of DeepSeek-V2, there still remains potential for further enhancement. Fortunately, these limitations are expected to be naturally addressed with the development of more advanced hardware."







