
AMD's Radeon RX 7000-series and the RDNA 3 architecture launched in late 2022, starting with the RX 7900 XTX and RX 7900 XT. Ove the next year and a half, numerous other cards have joined the series, powering some of the best graphics cards. You can see how the GPUs rank against other generations and competitors in our GPU benchmarks hierarchy, and we're now looking forward to the future RDNA 4 GPUs.
But let's not get ahead of ourselves. AMD's full lineup of RDNA 3 cards consists of seven different models. We've tested and reviewed them all, from the fastest RX 7900 XTX down to the lowly RX 7600 and everything in between. Let's get to the details.
AMD RDNA 3 / Navi 3x at a Glance
- Up to 96 CUs / 12,288 shaders
- 50% better performance per watt than RDNA 2
- Double the ALU count per CU
- GPU chiplet architecture
- Up to 96MB of Infinity Cache
AMD RX 7000-series specifications
With all the AMD RDNA 3 GPUs now launched and available worldwide, here are the core specifications.
The previous generation RDNA 2 and RX 6000-series GPUs had four GPU designs spread out across a full dozen different graphics card models — and that's not counting integrated graphics solutions. AMD RDNA 3 trims things down somewhat, with three primary GPUs and seven different graphics card models (plus some integrated versions).
The three GPU designs are called Navi 31, Navi 32, and Navi 33, going from highest performance to lowest performance. The largest die has three different models, while the other two only have two models. But there are some significant differences in how AMD gets there.
AMD RDNA 3 uses GPU chiplets for the first time, at least on the top two configurations. Navi 31 and 32 each have a large GCD (Graphics Compute Die), with anywhere from three to six MCD (Memory Cache Die) chiplets. The smallest die, Navi 33, retains the traditional monolithic die.
Each MCD offers a 64-bit memory interface and 16MB of L3 cache. The MCDs link to the main GCD via AMD's Infinity Fabric, using what AMD calls the Infinity Fanout Bridge. It uses less power per bit than other external interfaces, though there's certainly a power penalty relative to monolithic designs. In effect, AMD saved money on the costs of manufacturing the MCDs on a prior generation process node, which in turn shrinks the size of the GCD.
While future designs could benefit from breaking up the GPU die into multiple chiplets, for this first generation of GPU chiplets it's basically a cost-saving measure. The Navi 33 die meanwhile still uses N6, a refinement of the N7 node used with RDNA 2, because it's small enough it wasn't worth the effort of breaking it into a GCD plus two MCDs.
Clock speeds haven't changed much from RDNA 2, though AMD has a two different clock domains this time — one for the shaders and one for the front-end. AMD's stated clock speeds are somewhat conservative this round, meaning you'll generally see higher clocks in most games. But there are games where you may not hit the boost clock, which is what we've listed — AMD also has a "Game Clock" that's even more conservative, but in practice it's not as meaningful.
The CUs and shader cores have received a big upgrade this generation, but curiously AMD doesn't directly call each of the potential ALU processors a shader. Instead, it lists a base value that's half of the effective rate. So as an example, the 6,144 GPU sahders in the RX 7900 XTX can at times behave more like 12,288 shaders. That's where the much higher compute comes from, more than doubling what was available with RDNA 2.
The top model has 61.4 teraflops of compute, and double that for FP16 workloads. Even the mid-tier 7800 XT has 37.3 teraflops of compute, which almost doubles what the RX 6800 XT offered. However, actual gaming performance doesn't scale directly in proportion to the theoretical compute. So, as an example, the RX 7800 XT ends up performing quite similarly to the RX 6900 XT.
Memory bandwidth on the 7900 XTX increased by over 50% relative to the RX 6950 XT. That's thanks to the move to a 50% wider interface, plus running the GDDR6 memory at 20 Gbps (versus 18 Gbps on the 6950). Effective memory bandwidth also improves thanks to the second generation Infinity Cache, which for most models decreased in size compared to RDNA 2. But that's mostly offset by higher throughput and other tweaks to the caching hierarchy.
AMD Radeon 7000 Performance

As we saw with the past two generations of AMD hardware, AMD targeted at least a 50% improvement in performance per watt with RDNA 3. While that might seem reasonably specific, it leaves plenty of wiggle room. For example, RDNA 2 delivered 50% better performance per watt than RDNA. Let's give some concrete examples of how that played out.
According to our GPU benchmarks hierarchy, the RX 6900 XT consumes 308W of power while delivering 130 fps at 1080p ultra, 106 fps at 1440p ultra, and 63 fps at 4K ultra. A lower-tier RX 6700 XT uses 215W and averages 96 fps, 71 fps, and 39 fps, while the RX 5700 XT consumes 214W while delivering 74 fps, 53 fps, and 29 fps at those same resolutions.
Do the math, and the 6900 XT provides a 22% to 50% improvement in performance per watt, while the 6700 XT only provides a 29% to 34% improvement. If we add in all the other RDNA and RDNA 2 GPUs as reference points, the potential spread for performance-per-watt improvements becomes even wider.
AMD has also discussed some architectural improvements. The ray tracing hardware improved, but not as much as we would have liked. The biggest change architecturally was the move to dual CUs with double the execution resources. AMD also added AI Accelerators that increase the throughput of FP16 and INT8 calculations — these share resources with the shader execution cores but optimize the data flow.
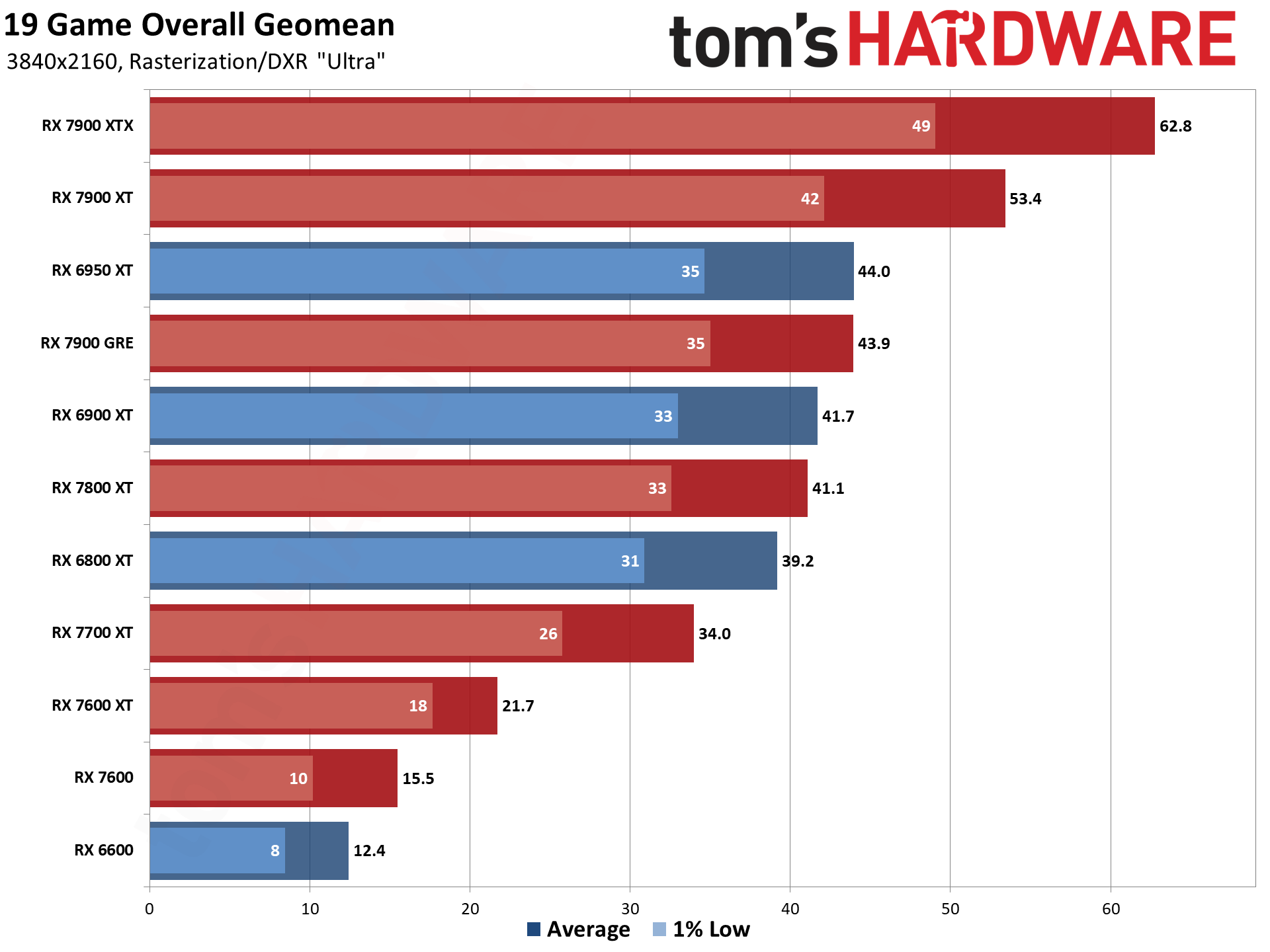
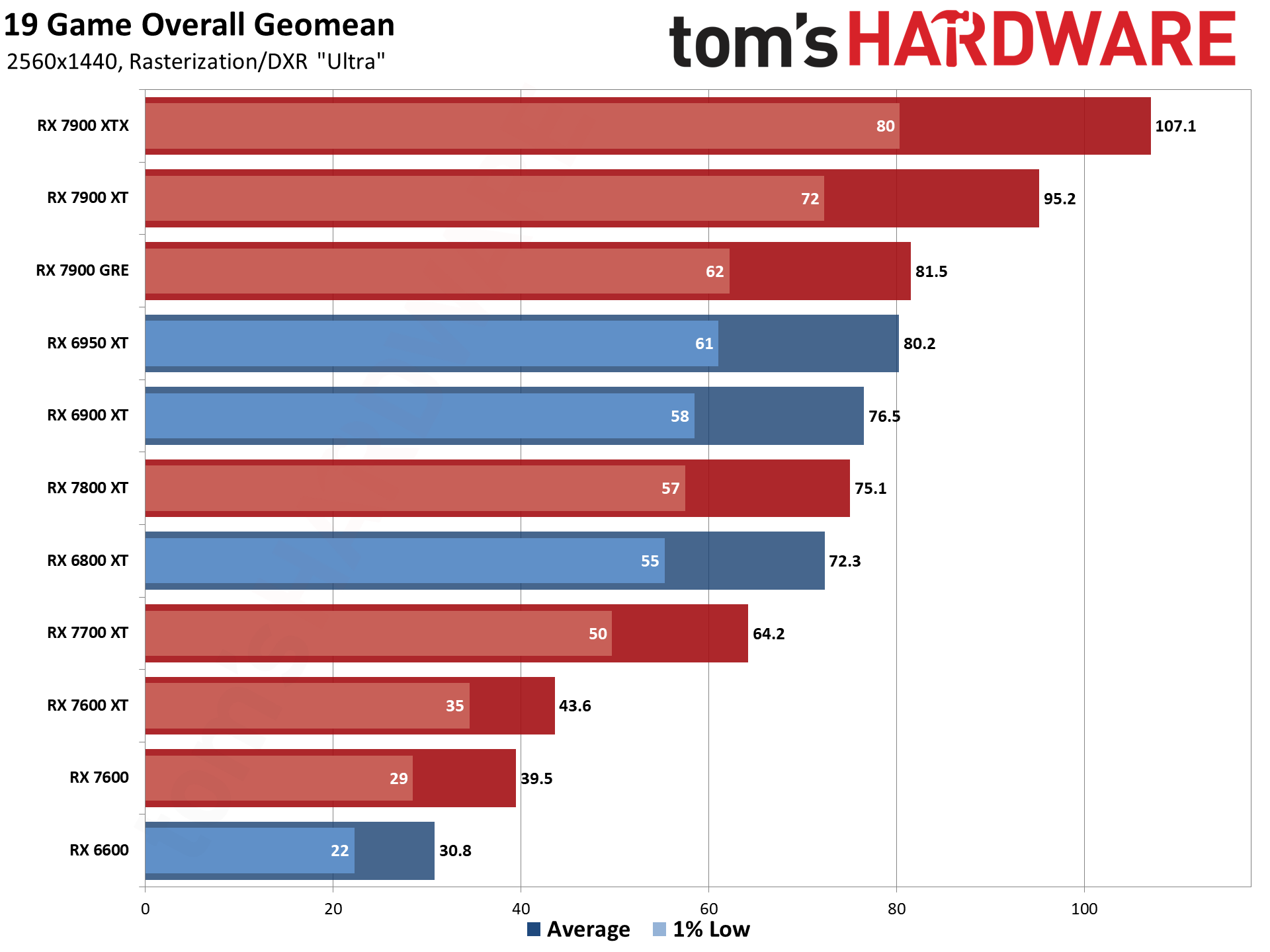
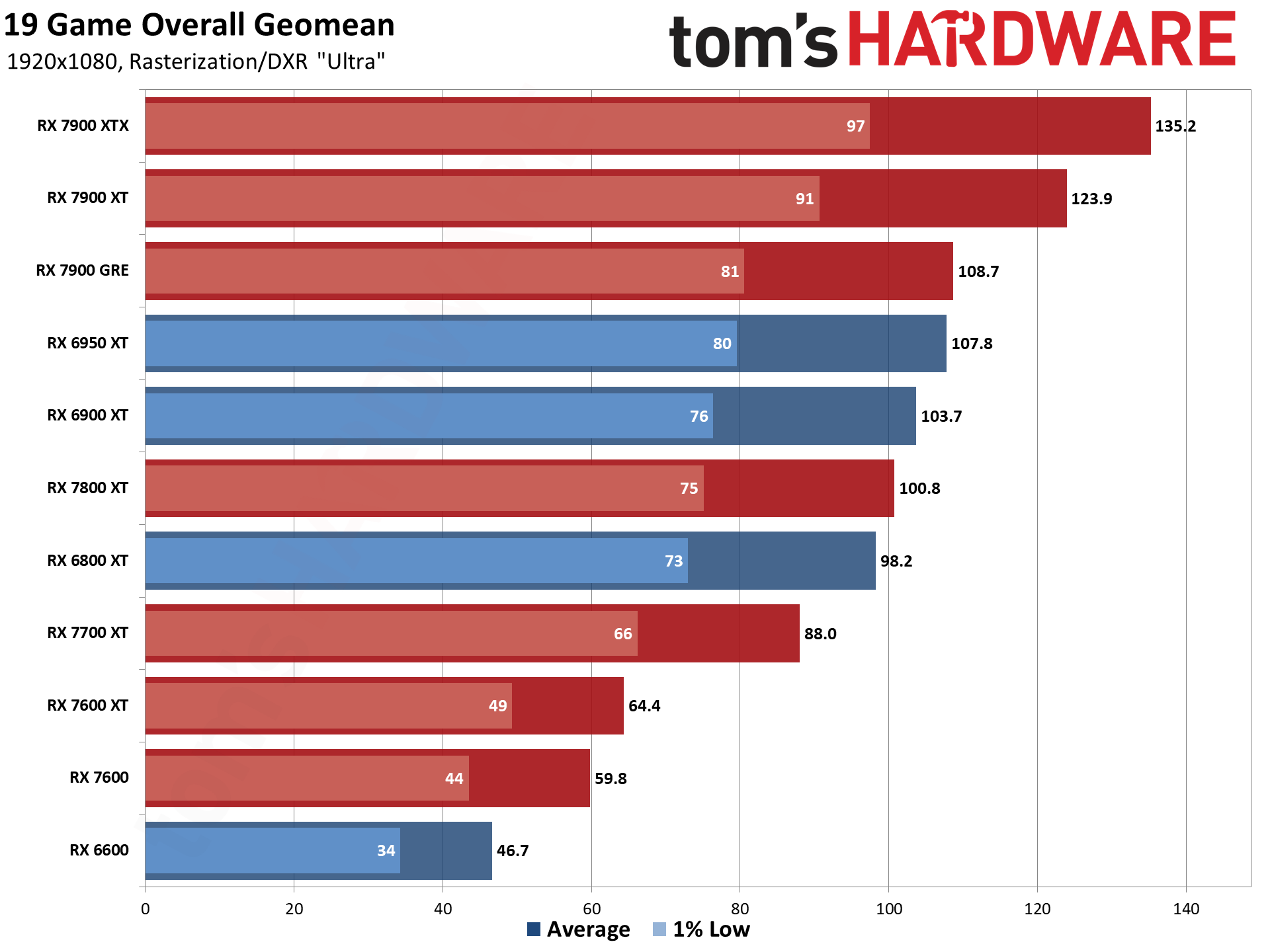
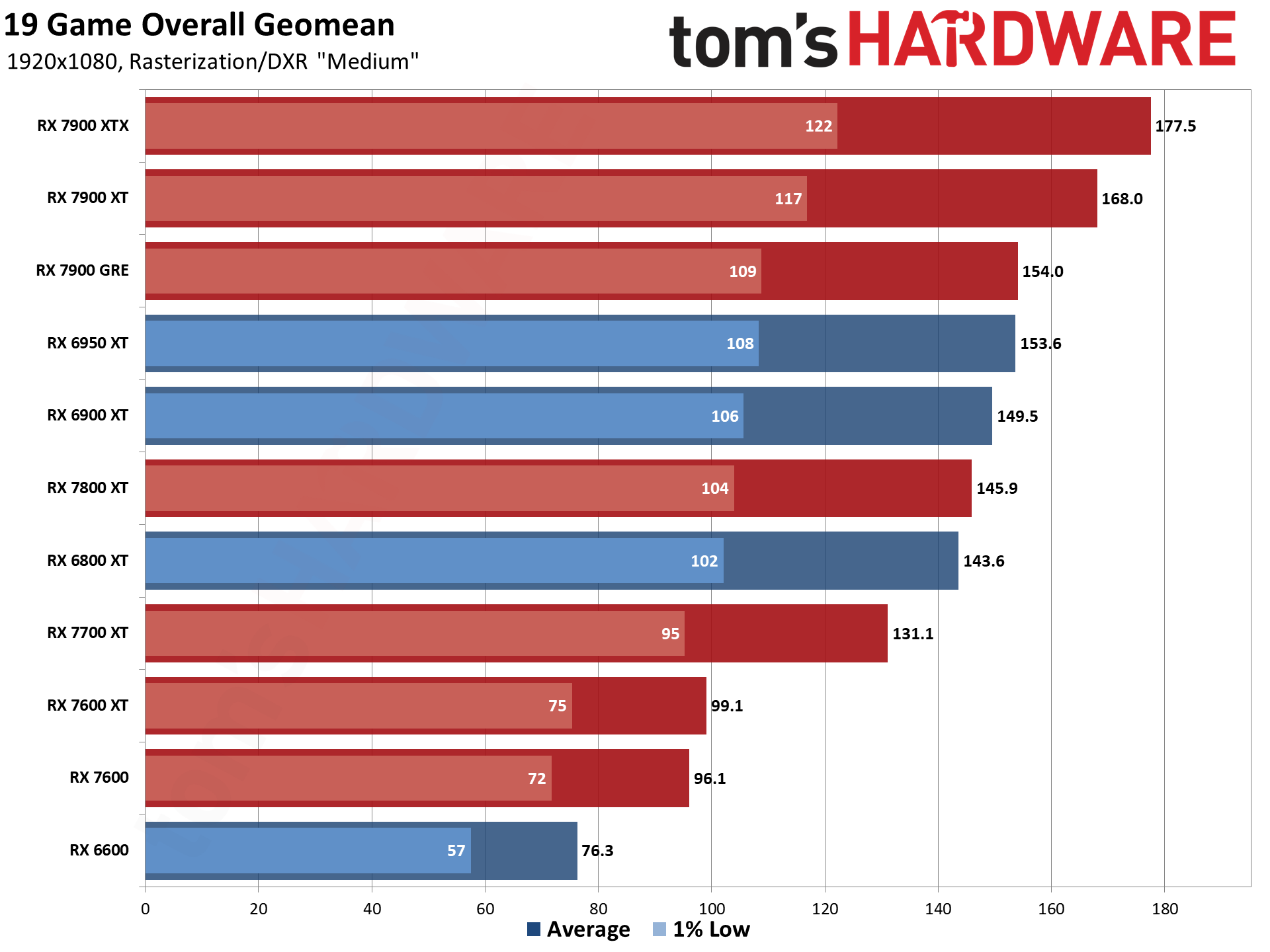
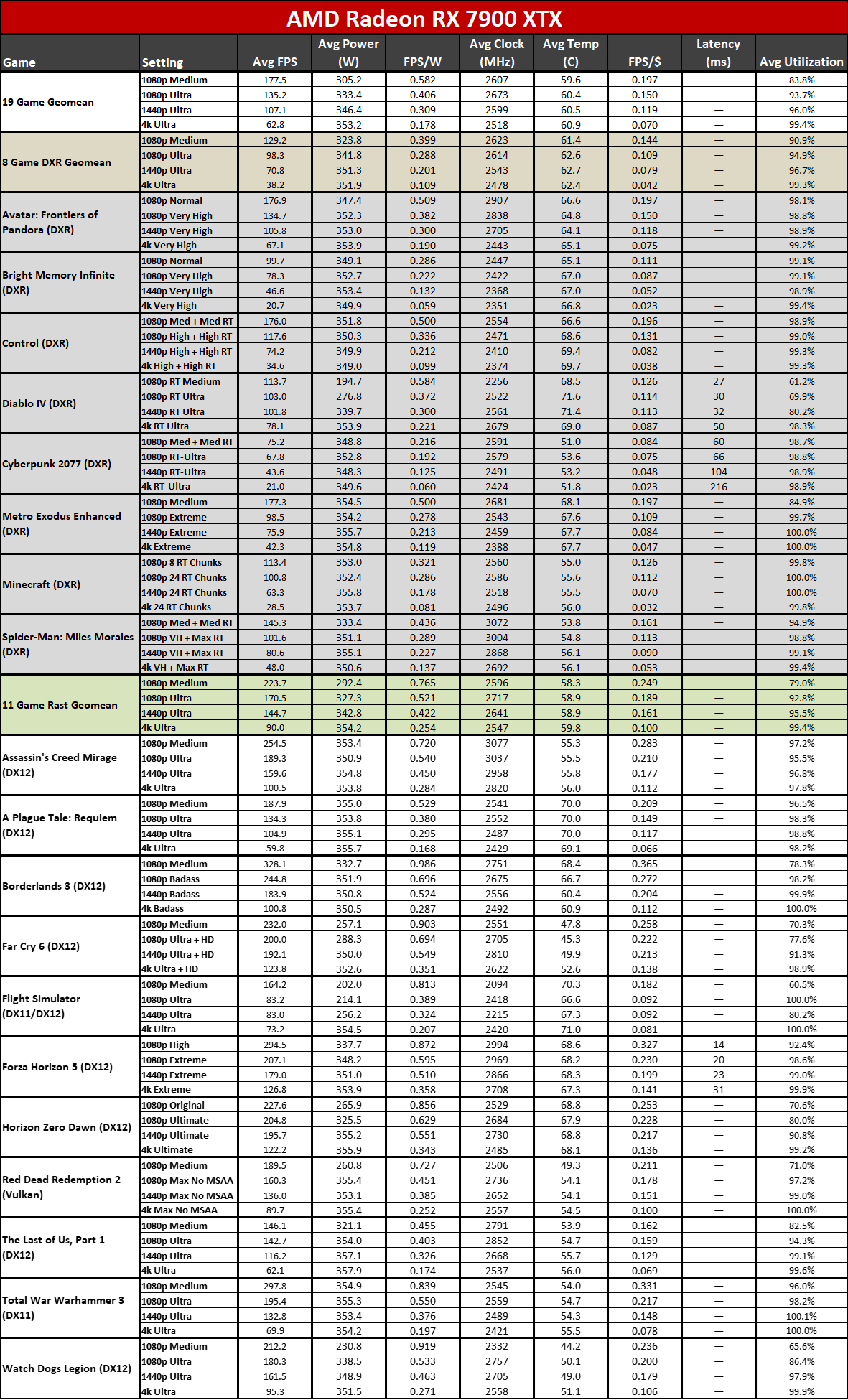
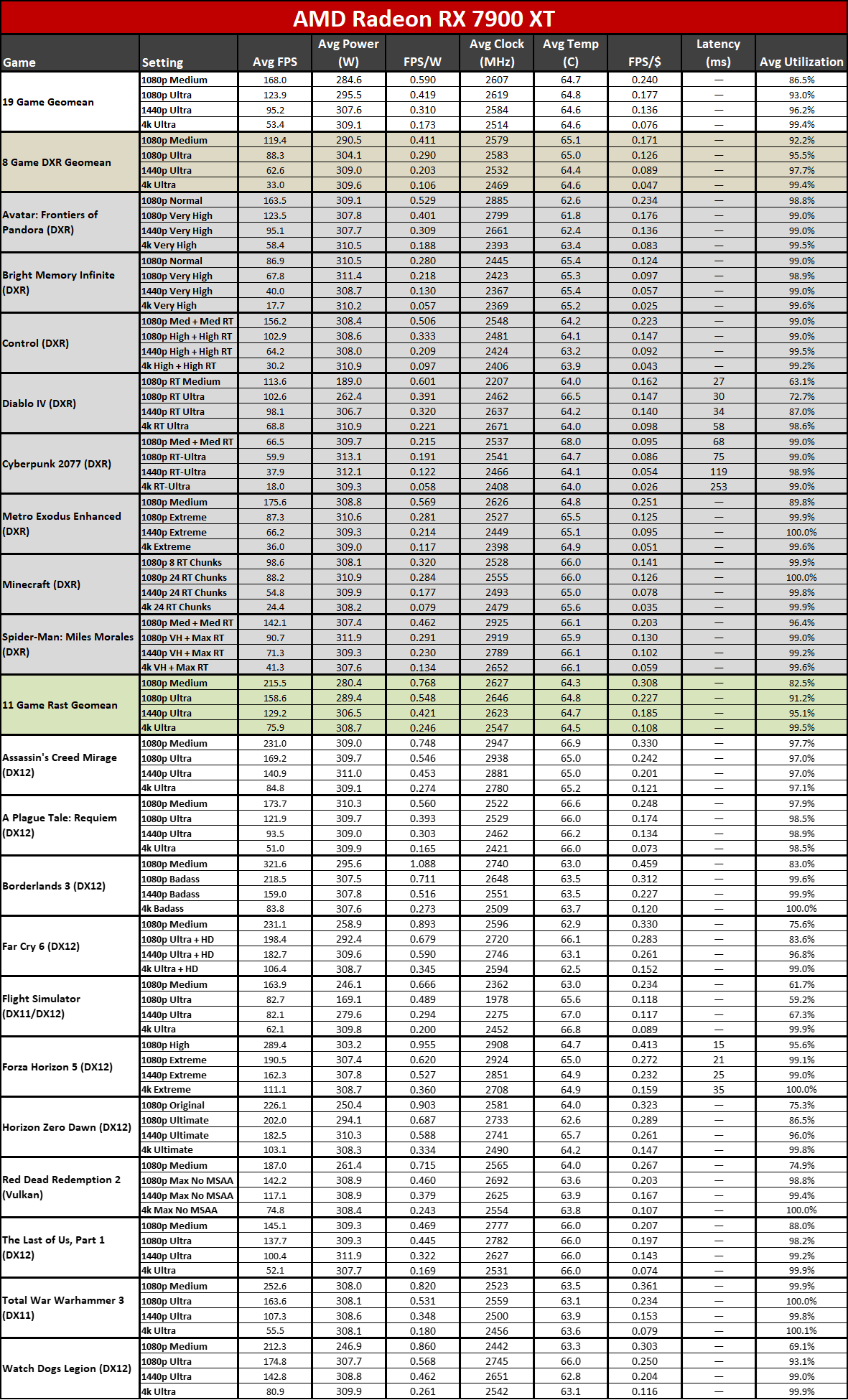
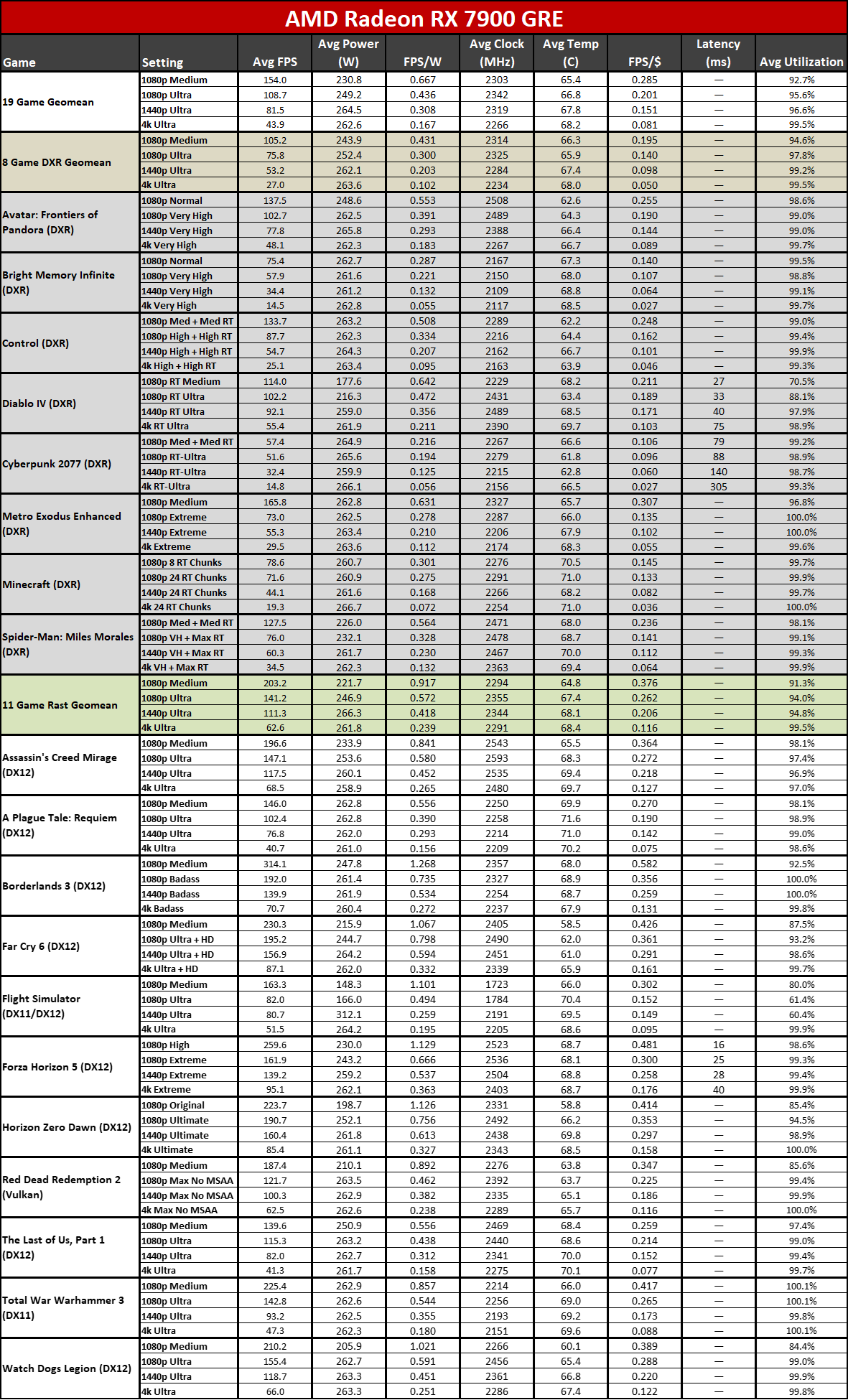
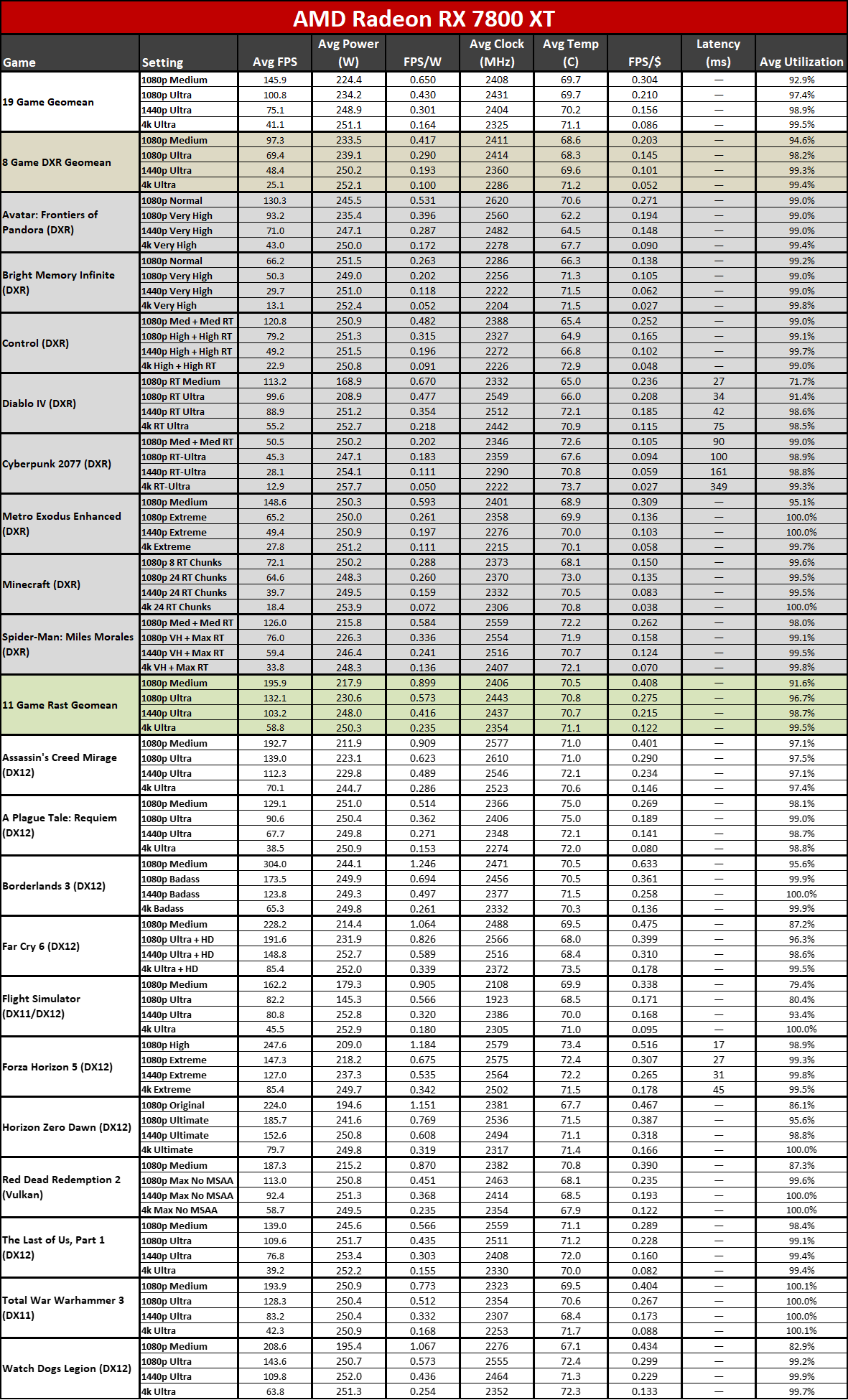
Now that all the RDNA 3 GPUs have launched, we can of course provide independent assessments of how they stack up — both in performance as well as performance per watt. The above charts show the overall results from our 19-game test suite. Below, we have tables of the individual test results. About half of the 6000-series GPUs are 'missing' because we don't have updated test results (yet), but we've provided enough data to put the 7000-series into context.
The top two GPUs, the 7900 XTX and 7900 XT, surpass the performance of anything offered by AMD's previous generation. That's chiefly thanks to both having more CUs, more VRAM, and more memory bandwidth than anything the prior gen offered. The 7900 XTX has 96 CUs and 24GB of memory with 960 GB/s of bandwidth; 7900 XT has 84 CUs and 20GB of memory with 800 GB/s of bandwidth. Compare that to the 6950 XT with 80 CUs, 16GB of memory, and 576 GB/s of bandwidth and it's easy to see why performance improved at the top.
Below that mark, things become less impressive. The 7900 GRE trades blows with the 6950 XT while the 7800 XT and 6800 XT land very close together. This shows the big concern with RDNA 3: Breaking off the memory controllers and cache to create GPU chiplets wasn't really about improving performance.
Similar CU counts end up delivering relatively similar performance, gen-on-gen. RX 7800 XT has 60 CUs and the 6800 XT has 72 CUs, so the older GPU had 20% more CUs. However, the new GPU also has higher clocks — 8% higher by specifications, but more like 5% in our test results. Overall, the 7800 XT ends up being about 5% faster, meaning the architectural improvements appear to only provide about a 10% improvement in overall performance.
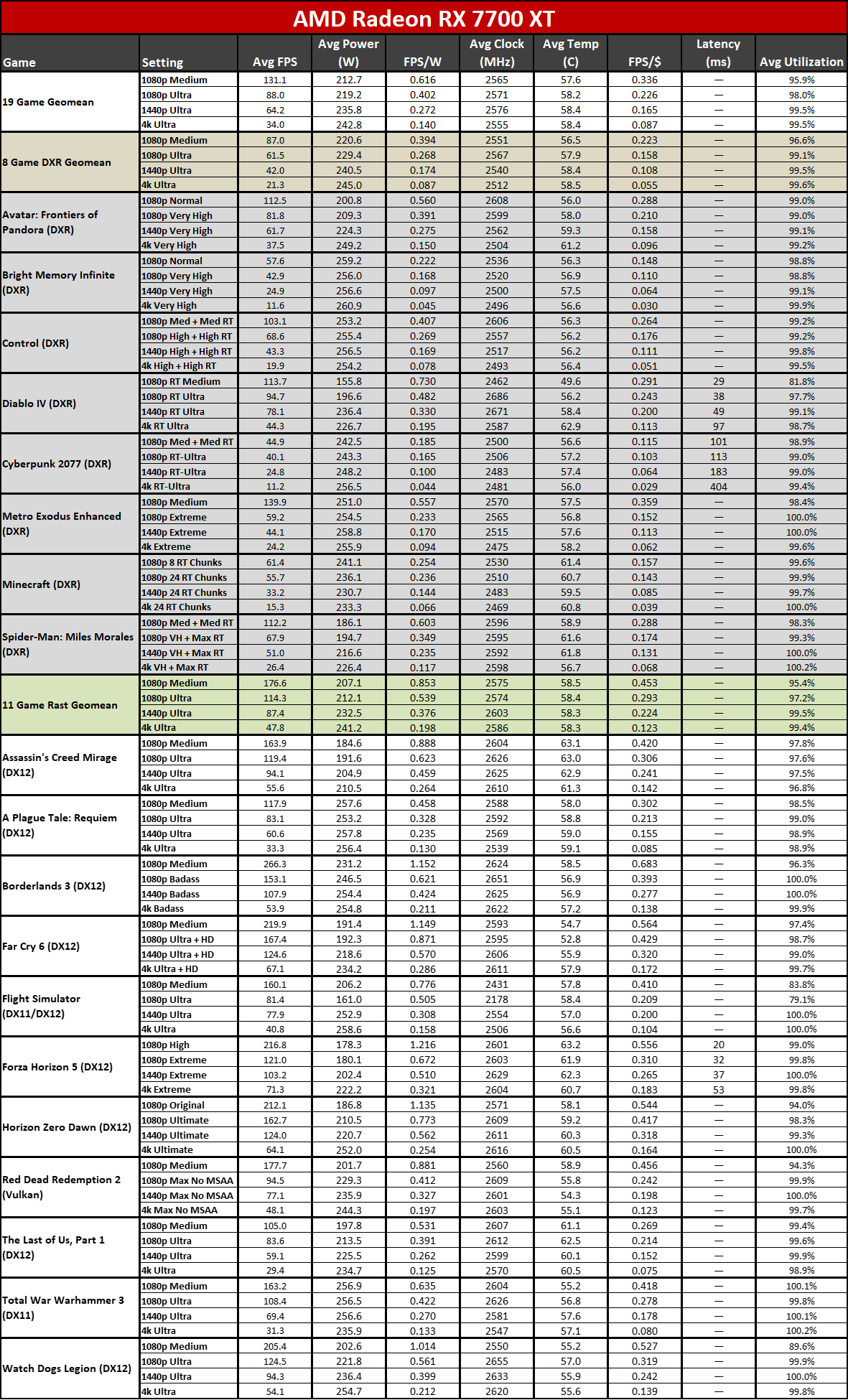
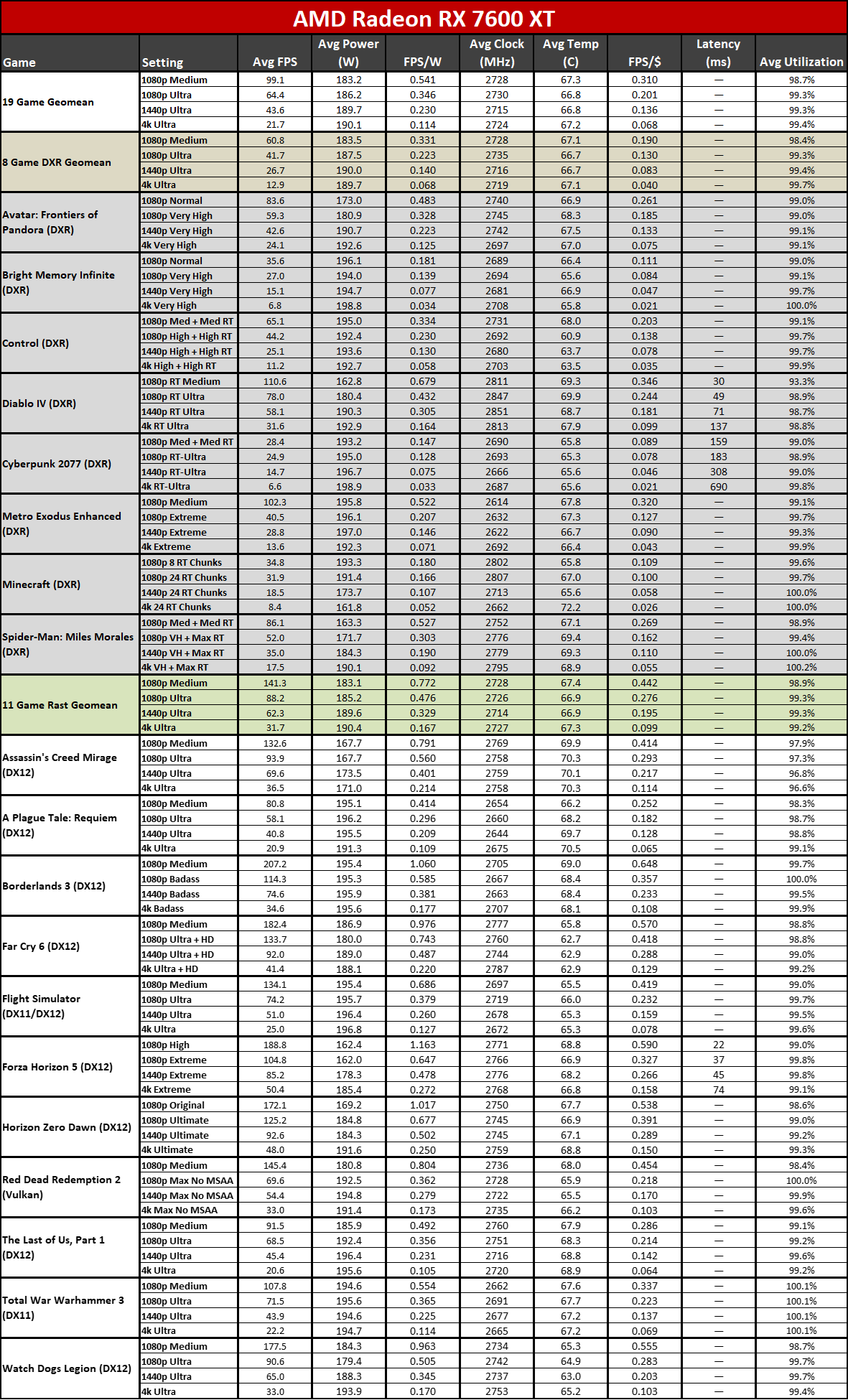
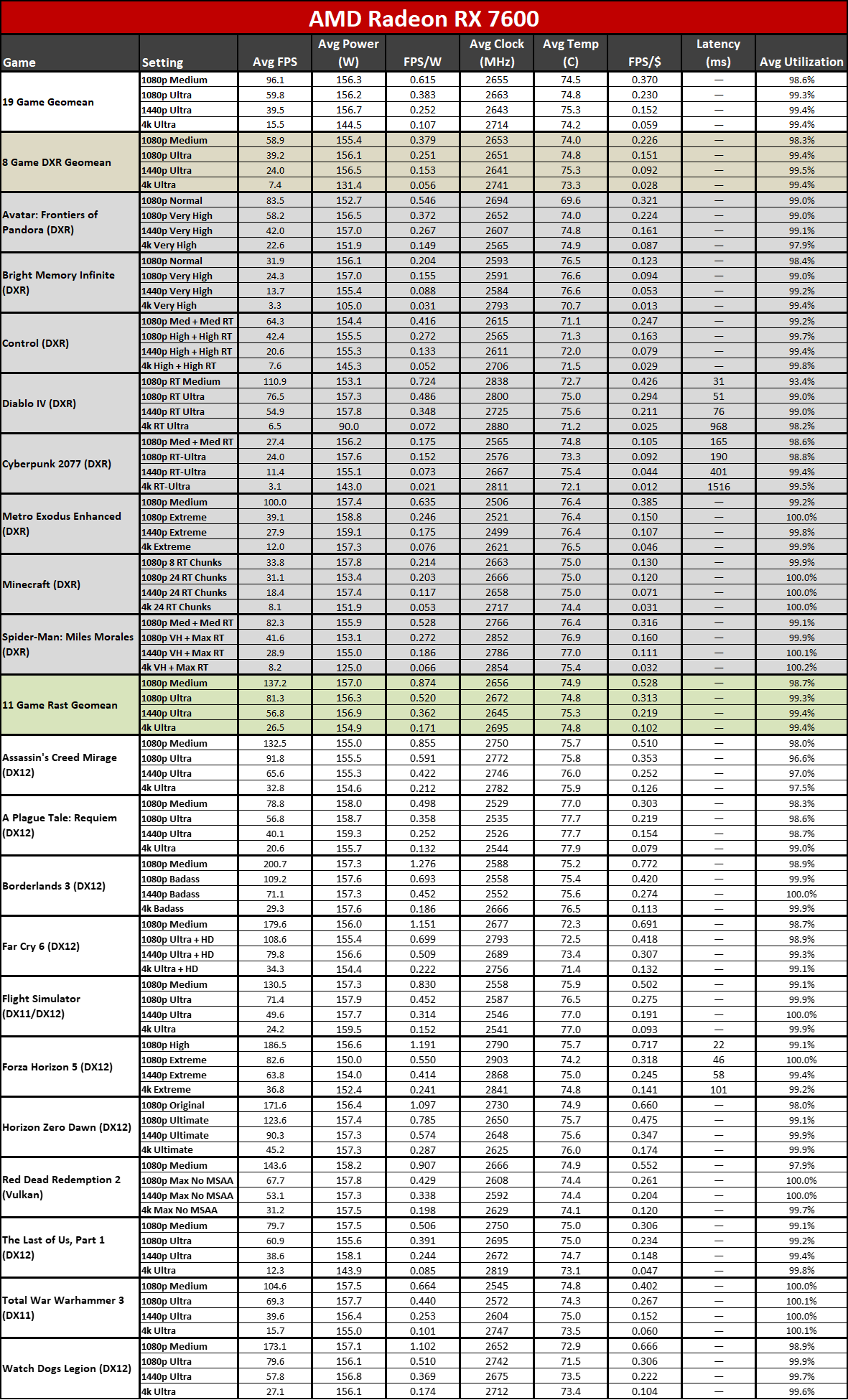
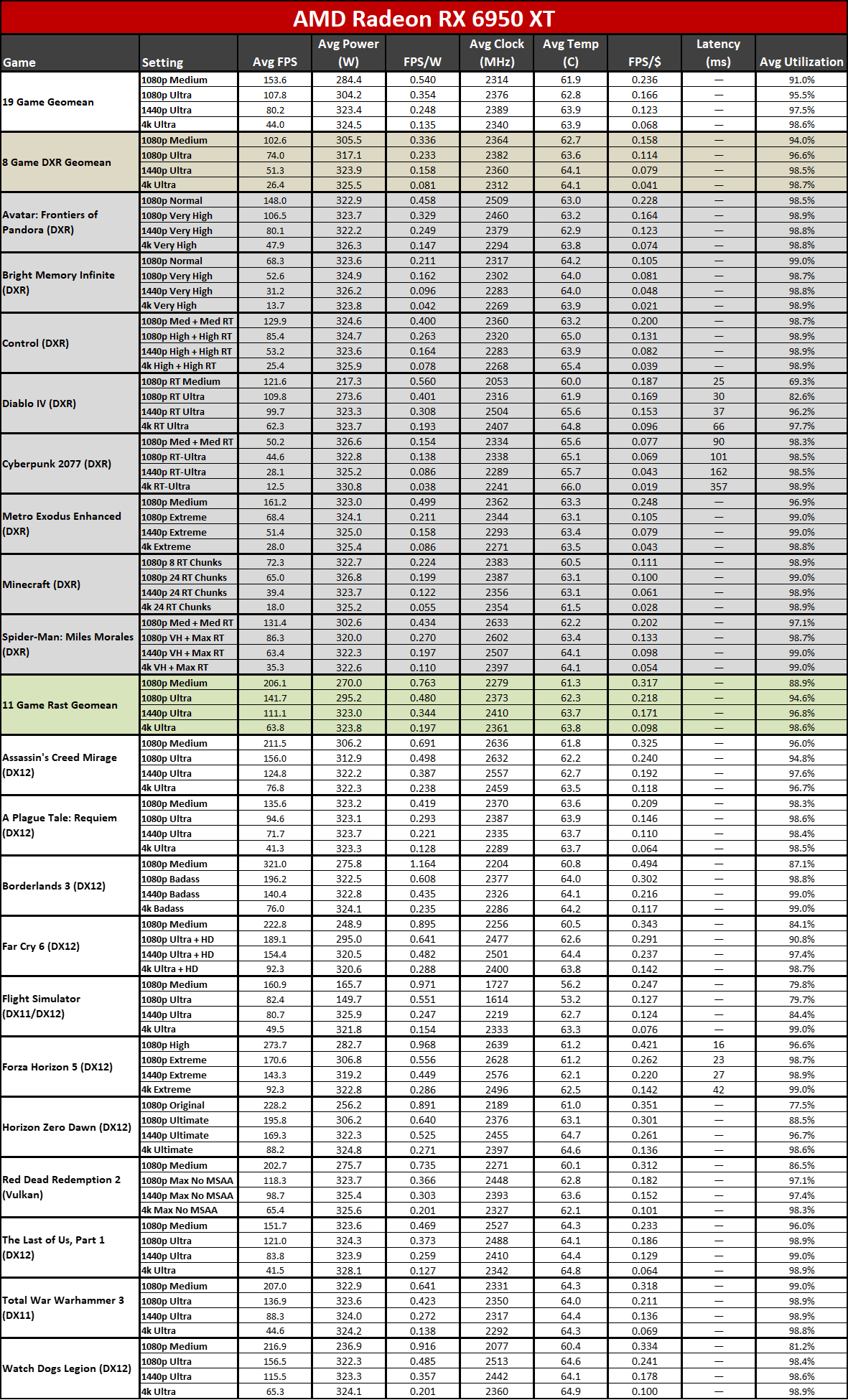
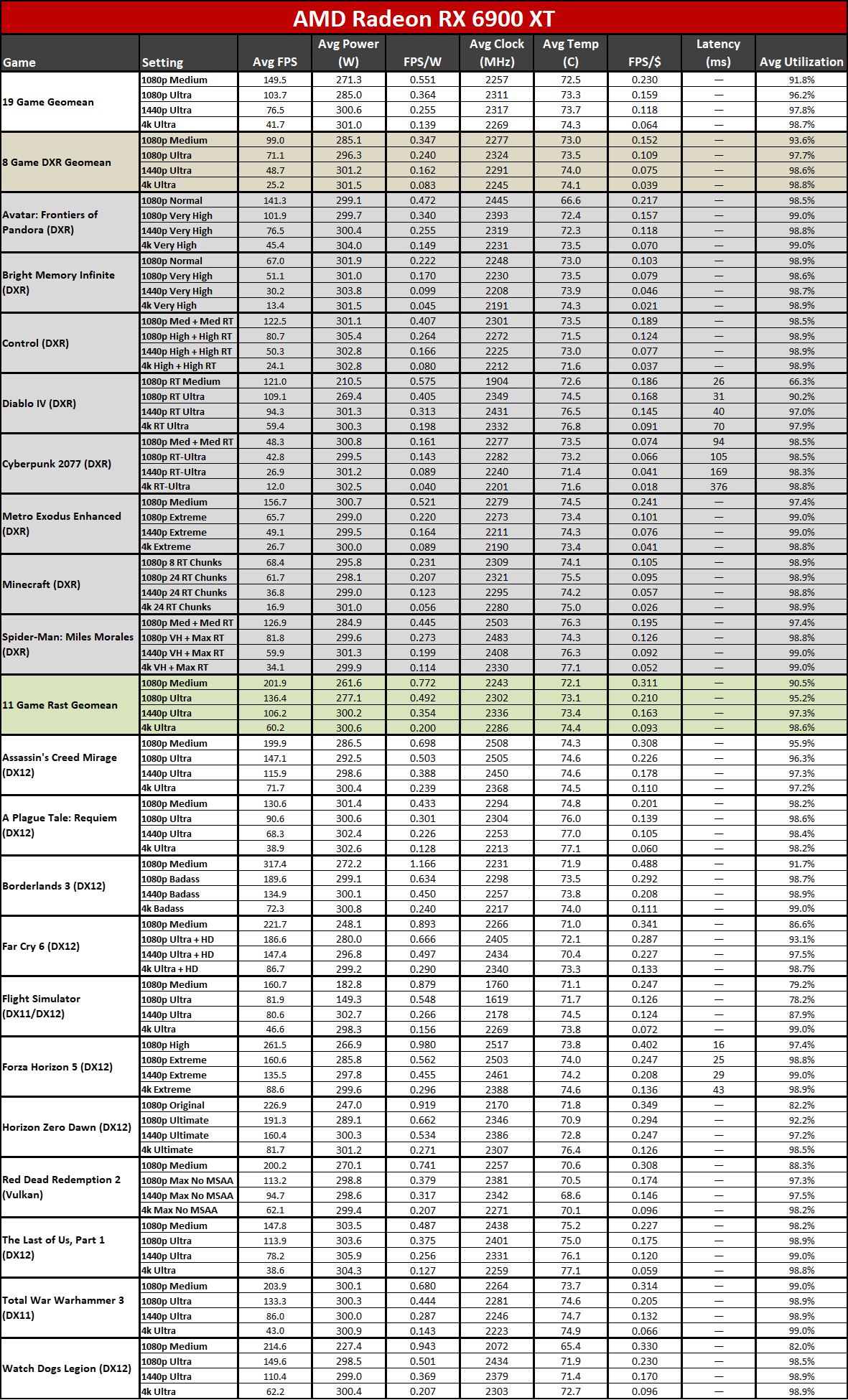
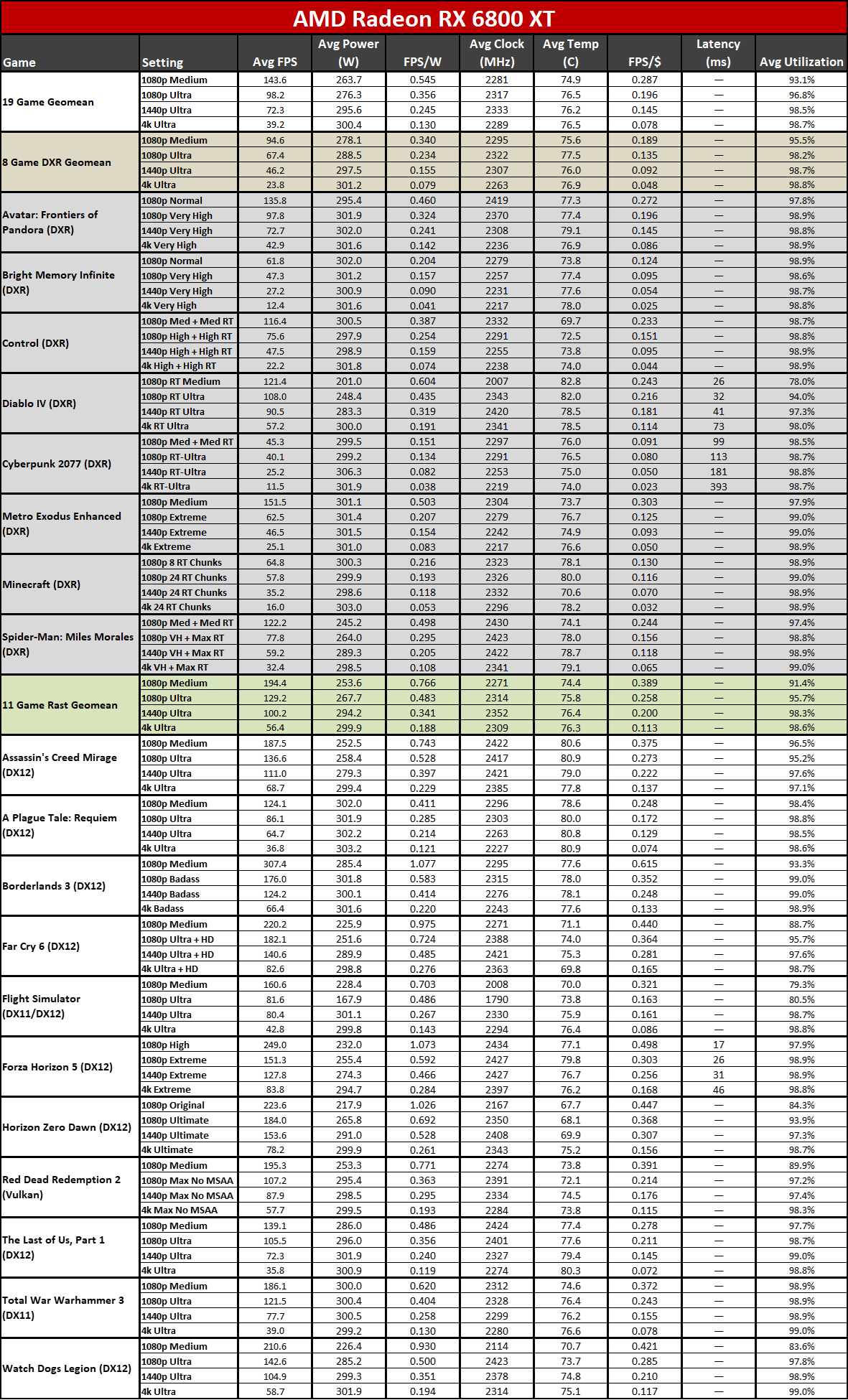
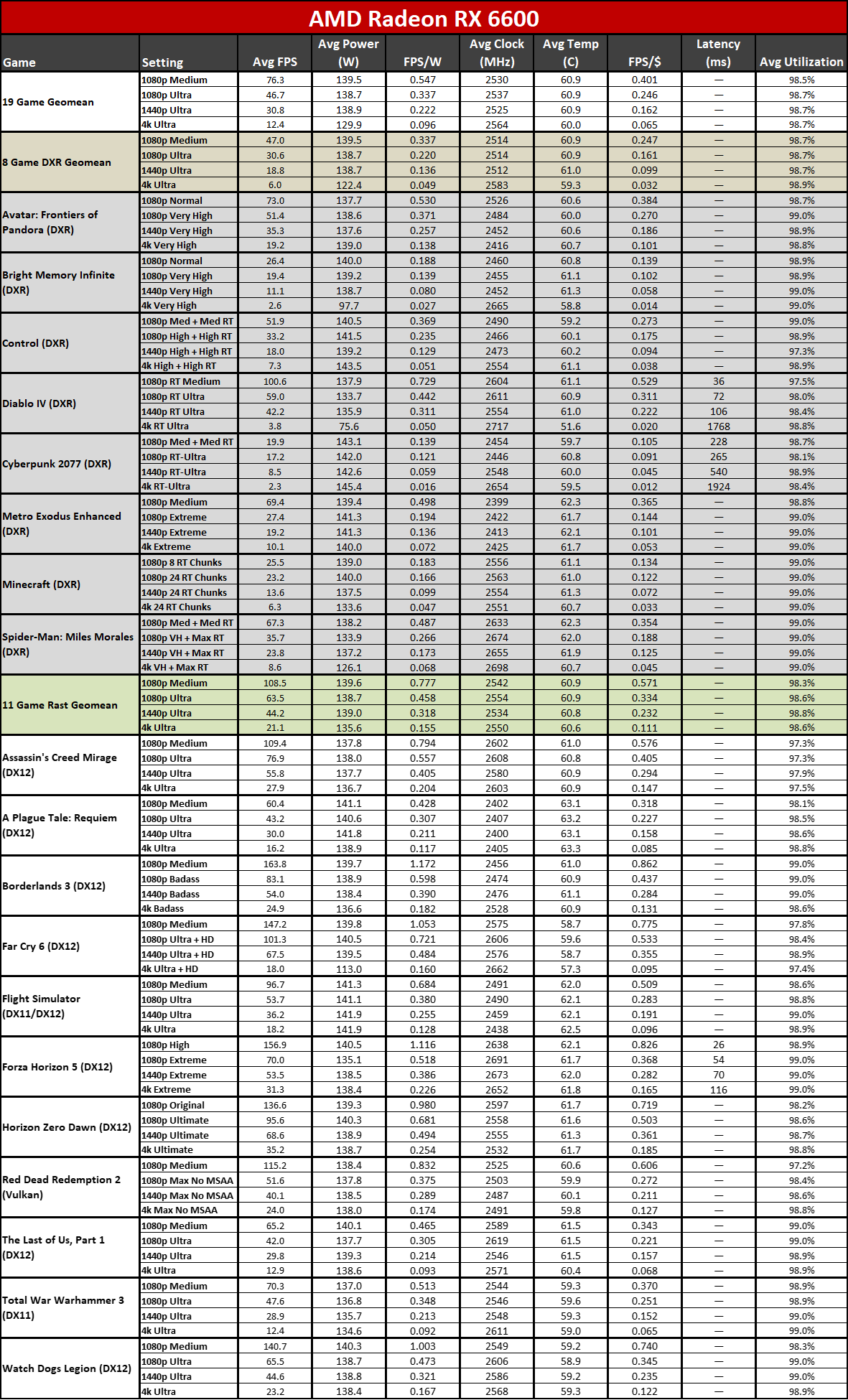
Here you can see the performance per watt metrics from our full testing suite. AMD claims up to a 50% improvement in perf/W, and if you pick the right GPUs to compre, you can get there... but it requires some serious cherry-picking of results.
The 7800 XT versus 6800 XT for example shows a gen-on-gen performance per watt improvement of just 19–25 percent overall. The 7900 XT versus 6900 XT improvement ranges from 7% (at 1080p medium) to 25% (at 4K ultra). If you want more than a 50% improvement, you need to do something like compare the RX 6600 with the RX 7700 XT at 4K ultra. Except the RX 6600 was never intended to be a 4K gaming card, so that's a pretty questionable comparison.
It's not that the RDNA 3 architecture represents a step back from RDNA 2; it's that it doesn't provide the big step forward that many hoped to see. RDNA 2 had better performance per watt than Nvidia's competing RTX 30-series, at least in rasterization games, but it also had a process node advantage. Nvidia leapfrogged AMD on process nodes and efficiency this round with the RTX 40-series, generally providing around 30~60 percent higher performance per watt.
AMD RDNA 3 Architecture: GPU Chiplets

One of the biggest architectural updates for RDNA 3 is something we've already mentioned — the move to GPU chiplets. There are good reasons for moving to multiple chiplets, though the overall net benefit largely depends on implementation. For this first generation of consumer GPU chiplets, AMD mostly seems to be focused on reducing costs.
Previous GPU designs were monolithic, meaning everything needed for the GPU to function came from a single piece of silicon. Because of that, GPUs build in a lot of redundancy, and chips get sold in "harvested" configurations. Navi 21 was used in the 6950 XT, 6900 XT, 6800 XT, and 6800, with up to 80 compute units (CUs) or as few as 60 CUs.
Interestingly, the Navi 21 die also has eight 32-bit memory interfaces, but AMD didn't release any Navi 21 variants with fewer memory channels. The same mostly applies to Navi 22, Navi 23, and Navi 24 — memory and cache sizes seem to have been an all-or-nothing thing. Perhaps yields on the memory controller were just really good, as the only GPU that didn't use all the memory channels possible was Navi 22 in the RX 6700 (non-XT), with a 160-bit interface instead of the full 192-bit interface.
With Navi 31 and 32, AMD will pull all of the memory interface and Infinity Cache blocks out of the main die and move them into separate dies. Each MCD contains a 64-bit GDDR6 interface and a 16MB chunk of Infinity Cache. There were rumors that the MCDs had the option to use 3D chip stacking with another 16MB die on top of the main MCD, but if that rumor was true, AMD never implemented such a configuration. The MCDs link with the GCD via AMD's Infinity Fabric, which will see some updates to the previous variants used in Ryzen CPUs.
Breaking out the Infinity Cache and GDDR6 memory interface has some clear advantages. Transistor densities scale best with logic circuits, less so with cache, and analog interfaces (i.e., for memory controllers) scale the worst. The on-package Infinity Fabric links on both the GCD and MCDs still require some die space, but any faulty memory controllers or cache blocks will no longer be a problem — they just get tossed.
Meanwhile, the MCDs will be made on TSMC's existing N6 process, which costs less than the newer N5 node, and die size won't even be a serious concern. The MCDs are only 38mm^2, meaning a 300mm N6 wafer should have enough room for about 1,600 MCDs, give or take. There's no real difficulty in simply tossing every faulty chip rather than worrying about building in redundancies.
The GCDs for Navi 31 and Navi 32 in turn shrink quite a bit compared to the prior generation, and on the costlier N5 node, that could be very helpful. AMD can still get around 180 of the larger Navi 31 GCD per wafer or nearly 300 of the smaller Navi 32. And it can still use harvested chips with fewer compute units or even MCDs to create lower-tier products — which is why we have three cards based on the Navi 31 GCD, and two using the Navi 32 GCD.
Had AMD stuck with monolithic designs, it likely would have ended up with Navi 31 using closer to 550mm square and getting maybe 100 chips per wafer. Since N5 wafers likely cost more than twice as much as N6, this should be an easy net win from a cost perspective. It also gives AMD more flexibility with cache sizes, at least on the higher-tier products. The stacked cache is only on the MCDs, leaving the GCD free to dissipate heat into the cooling setup — that's something 3D V-cache struggled with on its CPUs.
AMD RDNA 3 Architecture: Core Enhancements
AMD will have plenty of other changes in the core architecture of RDNA 3. AMD has stated that it will have a rearchitected compute unit and optimized shader architecture, though the latter doesn't provide much in the way of detail.
The compute units were overhauled, and in an approach that looks similar to what Nvidia did with Ampere, RDNA 3 CUs to have twice as many FP32 execution units. This yields a massive boost to theoretical compute, as AMD went from 80 RDNA 2 CUs and up to 5,120 GPU shaders to a maximum of 96 RDNA 3 CUs with 6,144 GPU shaders that are each twice as powerful as their predecessors. Even if the real-world benefit doesn't scale directly with theoretical compute, this should improve performance.
AMD's Ray Accelerators continue to lag behind what Nvidia and even Intel offer (per GPU processing cluster). Sharing the texture units with the BVH traversal hardware may have been okay for the first round of ray tracing hardware, but the second generation needed to be better. And it is... but not by much.
Overall, the optimizations and improvements made with RDNA 3 did deliver higher performance, but AMD continues to prioritize pure GPU shader compute with ray tracing and AI hardware seemingly an afterthought.
AMD RDNA 3 Architecture: AI Accelerators
We asked during our interview with AMD's Sam Naffziger whether or not we'd see tensor cores or their equivalent in AMD's consumer GPUs. To quickly recap, tensor cores are compute cores optimized for raw throughput, with a far more limited instruction set than GPU shaders. Nvidia's RTX cards have tensor cores for DLSS and other machine learning applications. Intel has followed suit with the Arc architecture's XMX cores (Xe Matrix eXtensions) used for XeSS and other deep learning software.
AMD isn't averse to providing such hardware in its GPUs, and it has tensor cores in the Instinct MI250X and MI300 data center GPUs. That's where most applications that will truly benefit from tensor cores run right now, but while there's a potential use case on consumer hardware, AMD seems content to mostly skip adding extra AI hardware for now.
What AMD did provide with RDNA 3 is what it's calling an AI Accelerator with WMMA (Wave Matrix Multiply Accumulate) instructions. These appear to repurpose the existing FP16 execution resources, so the raw theoretical throughput doesn't change, but the efficiency of running a bunch of FP16 calculations improves. We've seen this in our Stable Diffusion testing.
AMD Radeon 7000 Power Requirements
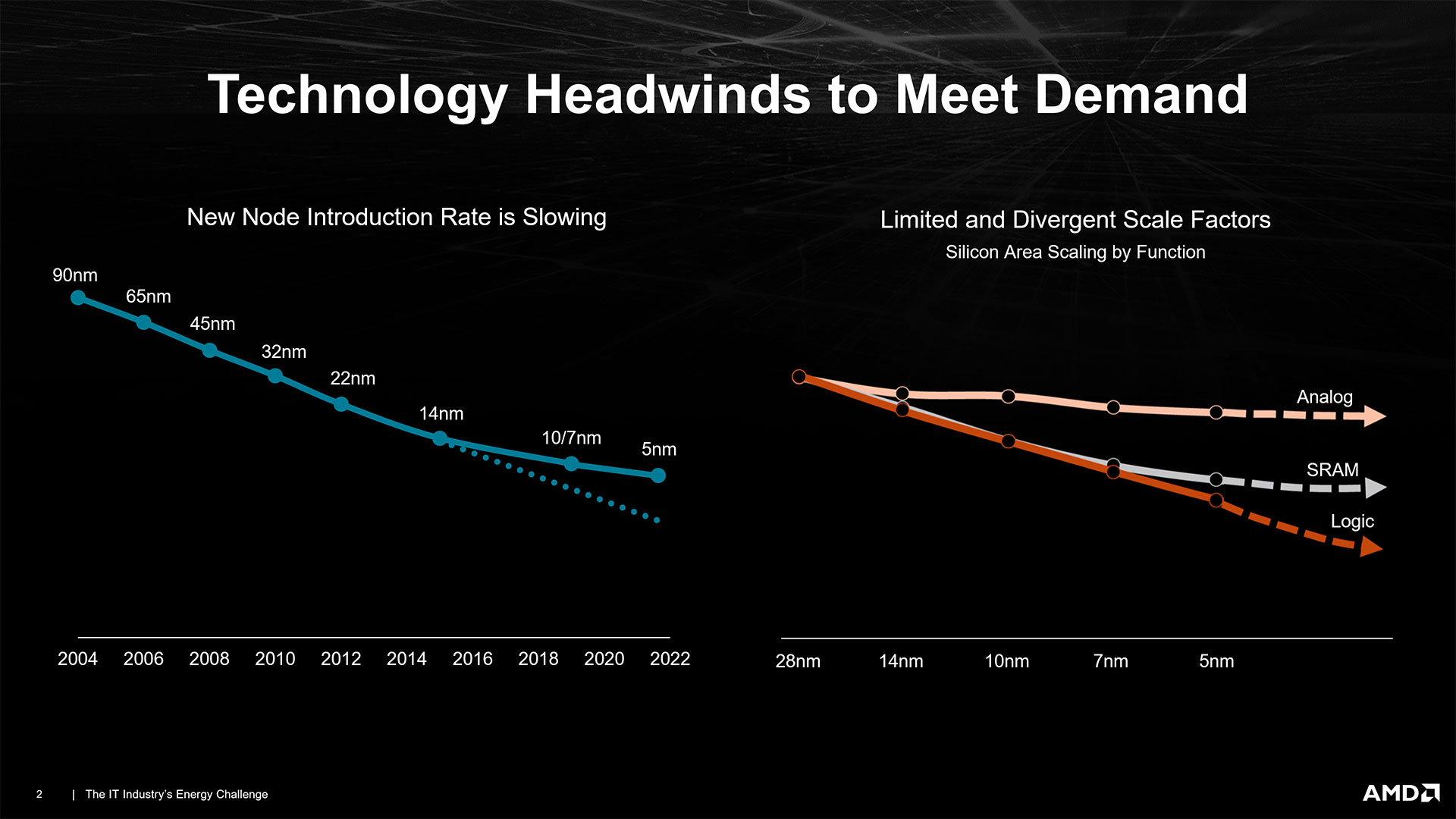
Moore's Law has largely focused on improving optimal transistor densities by reducing transistor sizes. While we continue to see progress, we've long since passed the point of doubling transistor counts every two years. Along with that, we've also seen a dramatic slowdown in power efficiency improvements.
It used to be that you'd get smaller transistors running at higher clocks using lower voltages and thus less power. Today, we get vague statements about 30% less power at the same performance or 15% more performance at the same power. Do the math and you'll see that those two things are not equivalent.
No company is immune to the side effects, and all signs indicate increased power consumption from the next-gen GPUs. The PCIe 5.0 power interface and upcoming power supplies that support it can supply up to 600W over a single 16-pin connector, for example, portending a broader industry shift to higher-power GPUs. Nvidia's RTX 4090 bumped power draw to 450W for the base model, and some factory overclocked cards even went so far as to include dual 16-pin connectors. AMD opted to completely skip the 16-pin connector, which ended up being a great move as far as we're concerned.
AMD's RDNA 3 pushed TBP (Total Board Power) slightly higher than RDNA 2, but only at the top of the spectrum. RX 7900 XTX has a 355W TBP, compared to 335W for the 6950 XT and 300W on the 6900 XT. The 7900 XT drops that to 315W, while the lower tier implementations are typically lower or similar TBPs to their predecessors. Curiously, even the RX 7600 has a 165W TBP, so there are no budget or low-power parts.
AMD's Sam Naffziger talked about this with us. "It's really the fundamentals of physics that are driving this," Naffziger explained. "The demand for gaming and compute performance is, if anything, just accelerating, and at the same time, the underlying process technology is slowing down pretty dramatically — and the improvement rate. So the power levels are just going to keep going up. Now, we've got a multi-year roadmap of very significant efficiency improvements to offset that curve, but the trend is there."
AMD has been able to drive slightly higher clocks with RDNA 3 while remaining as efficient as RDNA 2. AMD has long discussed its strategy of 'cross-pollinating' CPU and GPU design teams, bringing the best tech from both sides of the house to each new CPU and GPU design. The new RDNA 3 GPU cores are supposed to be "intrinsically more power efficient," but a business decision still needs to be made.
"Performance is king," stated Naffziger, "but even if our designs are more power-efficient, that doesn't mean you don't push power levels up if the competition is doing the same thing. It's just that they'll have to push them a lot higher than we will."
AMD Radeon 7000 Release Dates
The first RDNA 3 and RX 7000-series GPUs arrived in December 2022 with the 7900 XTX and XT models. The RX 7600 was the second distinct RDNA 3 die with Navi 33, launching in May 2023. We didn't see the middle-tier RDNA 3 cards until September 2023 when the RX 7800 XT and RX 7700 XT arrived. There was also a 7900 GRE in China in July 2023, which eventually arrived in the U.S. in February 2024, along with the RX 7600 XT that doubled the VRAM of the base non-XT card in January 2024.
There was likely a big delay in rolling out some of the RDNA 3 GPUs while AMD waited to clear out existing RDNA 2 inventory. Even nearly two years after the first cards launched, there are still RX 6000-series GPUs floating around the market offering decent value alternatives. RX 6700 XT and 6750 XT for example still generally outperform the newer RX 7600/7600 XT.
AMD Radeon 7000 Prices
How much do AMD's RX 7000-series graphics cards cost? The first models seemed to follow Nvidia's lead with higher price points than ever. The RX 7900 XTX launched at $999, with the step-down RX 7900 XT launching at $899. The latter wasn't a great value, and over time it has dropped $200 to just $699.
The budget RX 7600 meanwhile effectively took over the same price point — with extremely similar performance — as the existing RX 6650 XT. As noted above, RX 7800 XT and 7700 XT didn't come out until nine months after the Navi 31 parts, probably to allow the existing Navi 21 GPUs to clear out of the market. Pricing was similar to the existing street prices on the older GPUs as well, with $499 and $449 price points, but AMD did cut the RX 7700 XT price down to $399 six months after launch.
Some of the pricing still appears to have been impacted by the GPU-based cryptocurrency mining of the prior generation. Ethereum mining has ended, so GPUs aren't really being used much for cryptocurrency now (profits are in the toilet), but after seeing the prior generation GPUs often selling at twice their official MSRPs, AMD and Nvidia seem to have been overly greedy with the new prices. That also meant potential scalpers didn't really impact prices or availability, so there's at least a bit of a silver lining.






