
AMD announced a range of new products today at its Data Center and AI Technology Premiere event here in San Francisco, California. The company finally shared more details about its Instinct MI300A processors that feature 3D-stacked CPU and GPU cores on the same package with HBM, and a new GPU-only MI300X model that brings eight accelerators onto one platform that wields an incredible 1.5TB of HBM3 memory.
The company also made announcements about its 5nm EPYC Bergamo processors for cloud native applications and its EPYC Genoa-X processors with up to 1.1GB of L3 cache. All three of these products are available now, but AMD also has its EPYC Sienna processors for telco and the edge coming in the second half of 2023.

Combined with AMD's portfolio of Alveo and Pensando networking and DPUs, AMD has a full stack of products geared for AI workloads, placing it into direct contention with market leader Nvidia, its primary competitor for AI acceleration products, and Intel, which also offers several AI-acceleration solutions across a broad range of products.
This article focuses on the news around the MI300, but we'll add links to our other content shortly. We just received the information from AMD, so this article will be updated as we add more details.
AMD Instinct MI300


The Instinct MI300A is a data center APU that blends a total of 13 chiplets, many of them 3D-stacked, to create a single chip package with twenty-four Zen 4 CPU cores fused with a CDNA 3 graphics engine and eight stacks of HBM3 memory totaling 128GB. Overall the chip weighs in with 146 billion transistors, making it the largest chip AMD has pressed into production. The nine compute dies, a mix of 5nm CPUs and GPUs, are 3D-stacked atop four 6nm base dies that are active interposers that handle memory and I/O traffic, among other functions. The instinct MI300 will power the two-exaflop El Capitan supercomputer, which is slated to be the fastest in the world when it comes online later this year.


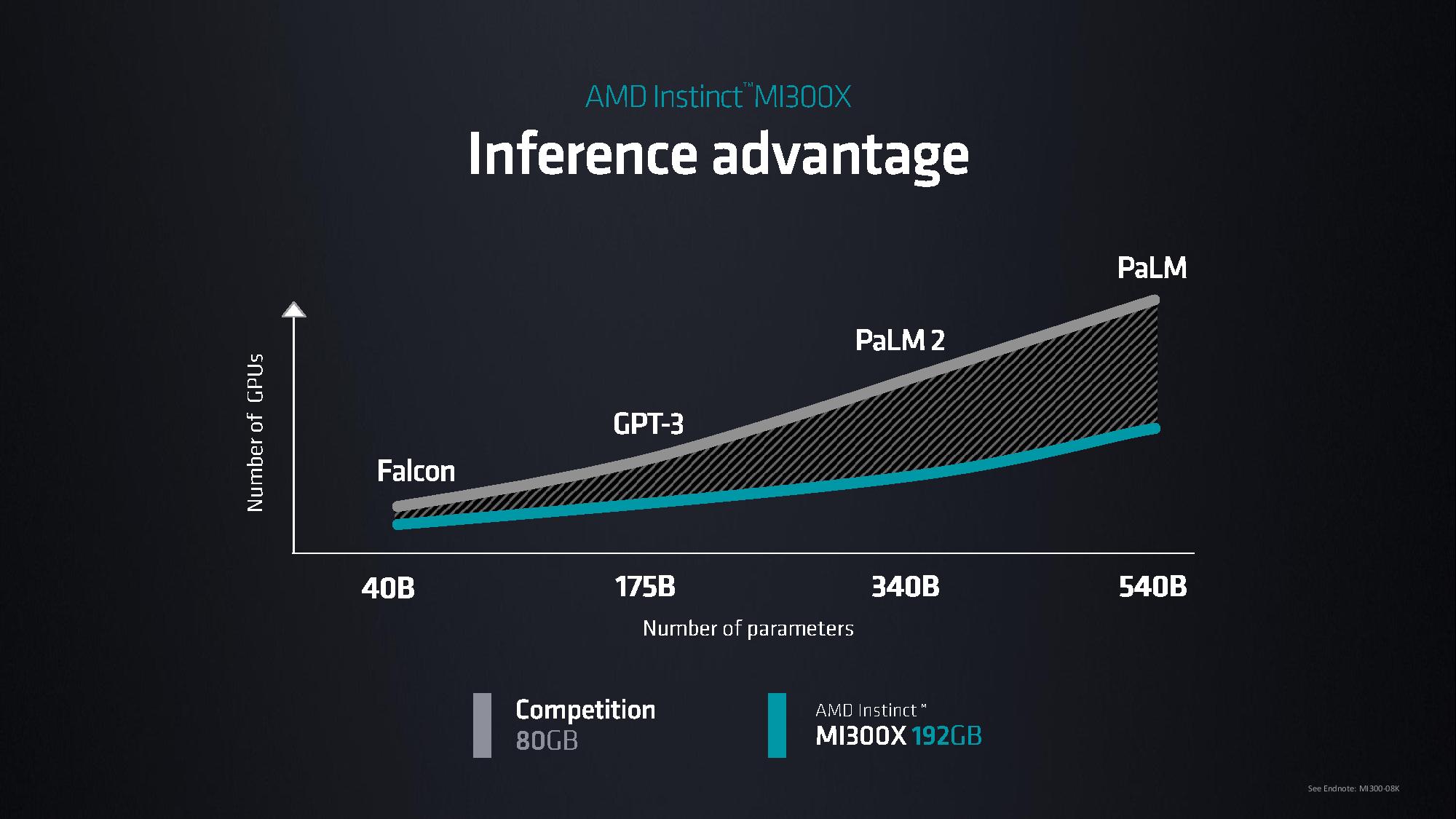
Today AMD announced a GPU-only variant, the MI300X, and presented several demos of its performance. The GPU-only MI300X is optimized for large language models (LLMs) and comes equipped with only CDNA3 GPU tiles paired with 192GB of HBM3 memory.
The voluminous memory capacity, spread across 24GB HBM3 chips, allows the chip to run LLMs up to 80 billion parameters, which AMD claims is a record for a single GPU. The chip delivers 5.2 TB/s of memory bandwidth across eight channels and 896 GB/s of Infinity Fabric Bandwidth. The MI300X offers 2.4X HBM density than the Nvidia H100 and 1.6X HBM bandwidth than the H100, meaning that AMD can run larger models than Nvidia's chips.
The chip is forged from 12 different chiplets on a mix of 5nm (GPU) and 6nm nodes (I/O die), which include eight GPUs and several I/O dies, for a total of 153 billion transistors.

The MI300A can run in several different modes, but the primary mode consists of a single memory domain and NUMA domain, thus providing uniform access memory for all the CPU and GPU cores. Meanwhile, the MI300X uses coherent memory between all of its GPU clusters. The key takeaway is that the cache-coherent memory reduces data movement between the CPU and GPU, which often consumes more power than the computation itself, thus reducing latency and improving performance and power efficiency.
AMD conducted a demo of a 40 billion parameter Falcon-40B model running on a single MI300X GPU, but no performance metrics were provided. Instead, the LLM wrote a poem about San Francisco, the location of AMD's event. AMD says this is the first time a model this large has been run on a single GPU.


AMD also announced the AMD Instinct Platform, which combines eight MI300X GPUs onto a single server motherboard with 1.5TB of total HBM3 memory. This platform is OCP-compliant, in contrast to Nvidia's proprietary MGX platforms. AMD says this open-sourced design will speed deployment.
MI300A, the CPU+GPU model, is sampling now. The MI300X and 8-GPU Instinct Platform will sample in the third quarter, and launch in the fourth quarter. We're still digging for more details - stay tuned for more in the coming hours.







