
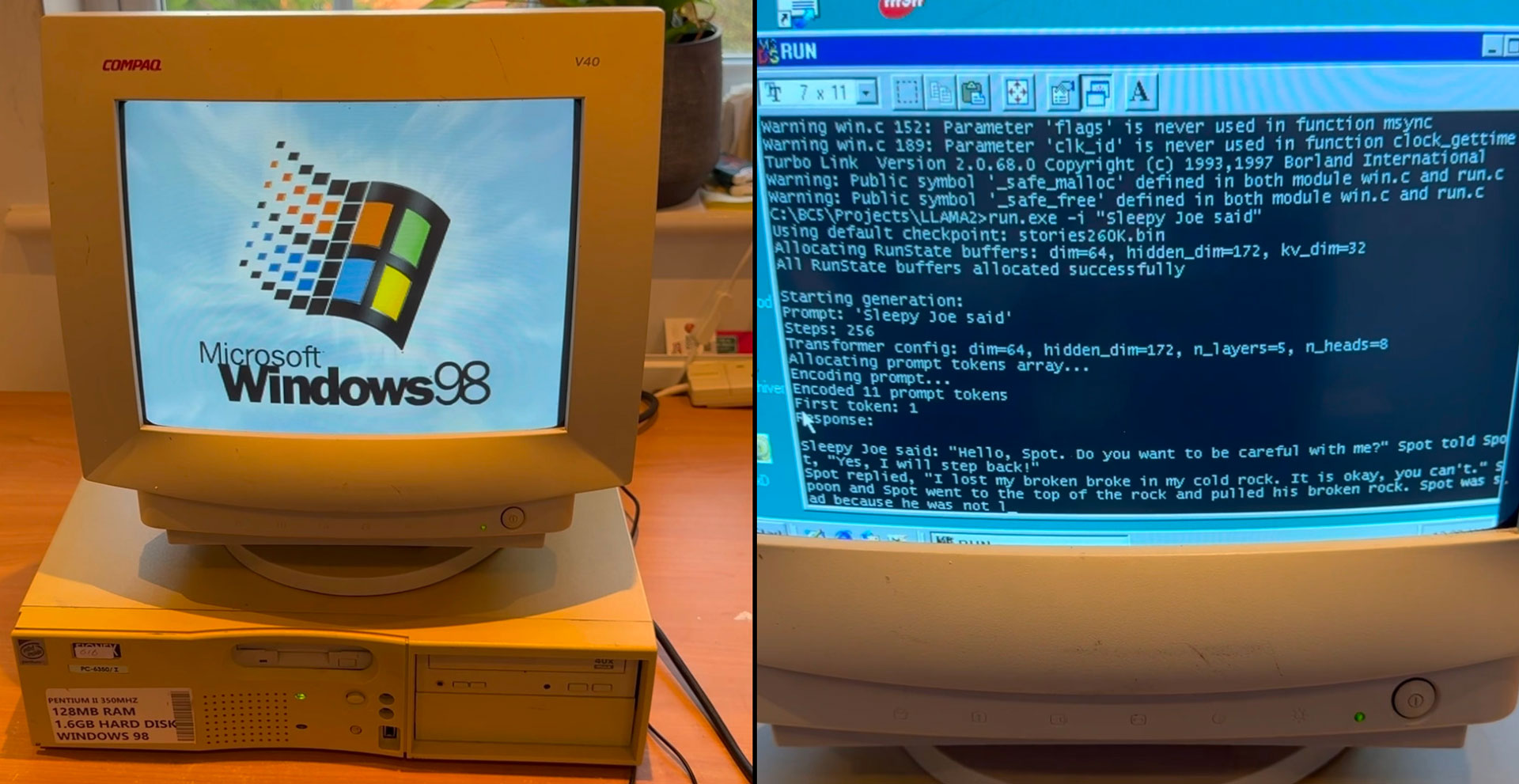
EXO Labs has penned a detailed blog post about running Llama on Windows 98 and demonstrated a rather powerful AI large language model (LLM) running on a 26-year-old Windows 98 Pentium II PC in a brief video on social media. The video shows an ancient Elonex Pentium II @ 350 MHz booting into Windows 98, and then EXO then fires up its custom pure C inference engine based on Andrej Karpathy's Llama2.c and asks the LLM to generate a story about Sleepy Joe. Amazingly, it works, with the story being generated at a very respectable pace.
LLM running on Windows 98 PC26 year old hardware with Intel Pentium II CPU and 128MB RAM.Uses llama98.c, our custom pure C inference engine based on @karpathy llama2.cCode and DIY guide 👇 pic.twitter.com/pktC8hhvvaDecember 28, 2024
The above eye-opening feat is nowhere near the end game for EXO Labs. This somewhat mysterious organization came out of stealth in September with a mission "to democratize access to AI." A team of researchers and engineers from Oxford University formed the organization. Briefly, EXO sees a handful of megacorps controlling AI as a very bad thing for culture, truth, and other fundamental aspects of our society. Thus EXO hopes to "Build open infrastructure to train frontier models and enable any human to run them anywhere." In this way, ordinary folk can hope to train and run AI models on almost any device – and this crazy Windows 98 AI feat is a totemic demo of what can be done with (severely) limited resources.
Since the Tweet video is rather brief, we were thankful to find EXO's blog post about Running Llama on Windows 98. This post is published as Day 4 of "the 12 days of EXO" series (so stay tuned).
As readers might expect, it was trivial for EXO to pick up an old Windows 98 PC from eBay as the foundation of this project, but there were many hurdles to overcome. EXO explains that getting data onto the old Elonex branded Pentium II was a challenge, making them resort to using "good old FTP" for file transfers via the ancient machine's Ethernet port.
Compiling modern code for Windows 98 was probably a greater challenge. EXO was glad to find Andrej Karpathy's llama2.c, which can be summarized as "700 lines of pure C that can run inference on models with Llama 2 architecture." With this resource and the old Borland C++ 5.02 IDE and compiler (plus a few minor tweaks), the code could be made into a Windows 98-compatible executable and run. Here's a GitHub link to the finished code.
35.9 tok/sec on Windows 98 🤯This is a 260K LLM with Llama-architecture.We also tried out larger models. Results in the blog post. https://t.co/QsViEQLqS9 pic.twitter.com/lRpIjERtSrDecember 28, 2024
One of the fine folks behind EXO, Alex Cheema, made a point of thanking Andrej Karpathy for his code, marveling at its performance, delivering "35.9 tok/sec on Windows 98" using a 260K LLM with Llama architecture. It is probably worth highlighting that Karpathy was previously a director of AI at Tesla and was on the founding team at OpenAI.
Of course, a 260K LLM is on the small side, but this ran at a decent pace on an ancient 350 MHz single-core PC. According to the EXO blog, Moving up to a 15M LLM resulted in a generation speed of a little over 1 tok/sec. Llama 3.2 1B was glacially slow at 0.0093 tok/sec, however.
BitNet is the bigger plan
By now, you will be well aware that this story isn't just about getting an LLM to run on a Windows 98 machine. EXO rounds out its blog post by talking about the future, which it hopes will be democratized thanks to BitNet.
"BitNet is a transformer architecture that uses ternary weights," it explains. Importantly, using this architecture, a 7B parameter model only needs 1.38GB of storage. That may still make a 26-year-old Pentium II creak, but that's feather-light to modern hardware or even for decade-old devices.
EXO also highlights that BitNet is CPU-first – swerving expensive GPU requirements. Moreover, this type of model is claimed to be 50% more efficient than full-precision models and can leverage a 100B parameter model on a single CPU at human reading speeds (about 5 to 7 tok/sec).
Before we go, please note that EXO is still looking for help. If you also want to avoid the future of AI being locked into massive data centers owned by billionaires and megacorps and think you can contribute in some way, you could reach out.
For a more casual liaison with EXO Labs, they host a Discord Retro channel to discuss running LLMs on old hardware like old Macs, Gameboys, Raspberry Pis, and more.







